Though both the schemamapper and a pythoncaller can accomplish to create, map and 'remove' attributes, the newly mapped attributes are hidden and the removed attributes are still exposed (with only missing values). When I write this to excel I get empty columns but the columns are still created. I don't want to use the hide attributes option in the pythoncaller; I want the attributes to be written and not written to be dependent on a list I read from another file.

Solved
I want to let an external source (excel-sheet) determine which attributes to write.
Best answer by todd_davis
You are right. Excel is pretty terrible as setting data types and field lengths and you would probably just get all character fields in SDE. It would work but you date, integers, doubles probably wouldn't work.
I am assuming that you excel reference just is a standard excel table where column 1 hold the first field name, column 2 holds the second field name etc. Rather than column 1 contains all the field names, column 2 holds data type., column 3 holds the length.
oh yes it is.
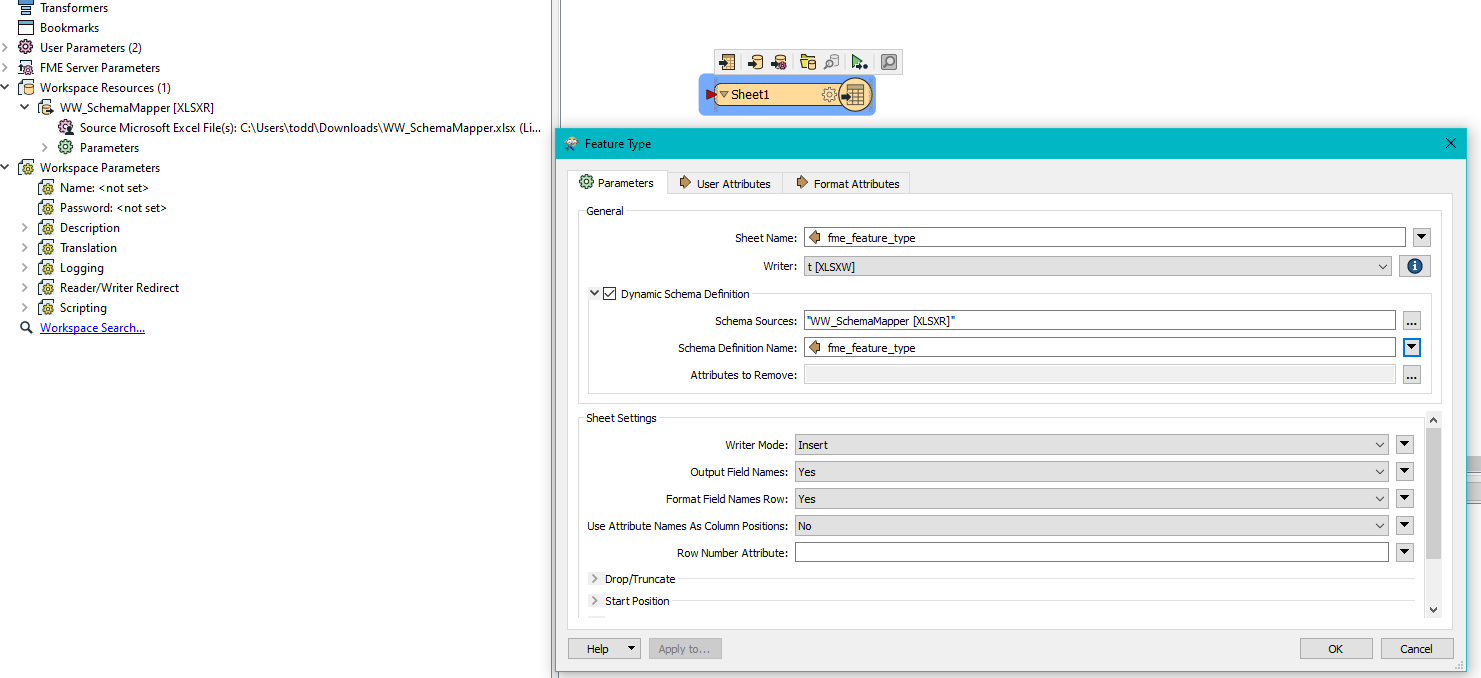
Here is an example of utilising a spreadsheet containing name, data type and field length. You will notice I am using fme data type. There are also native data types (native_data_type) like that for SDE, the provide further clarification as an integer. Hint: Use a featurereader to read a SDE table and look at the info coming out of the schema port to see how this is all structure and it will inform you of what you might need when writing a schema out dynamically.
But here is the example, and you should be able to build in some of the other logic you mentioned.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.