")

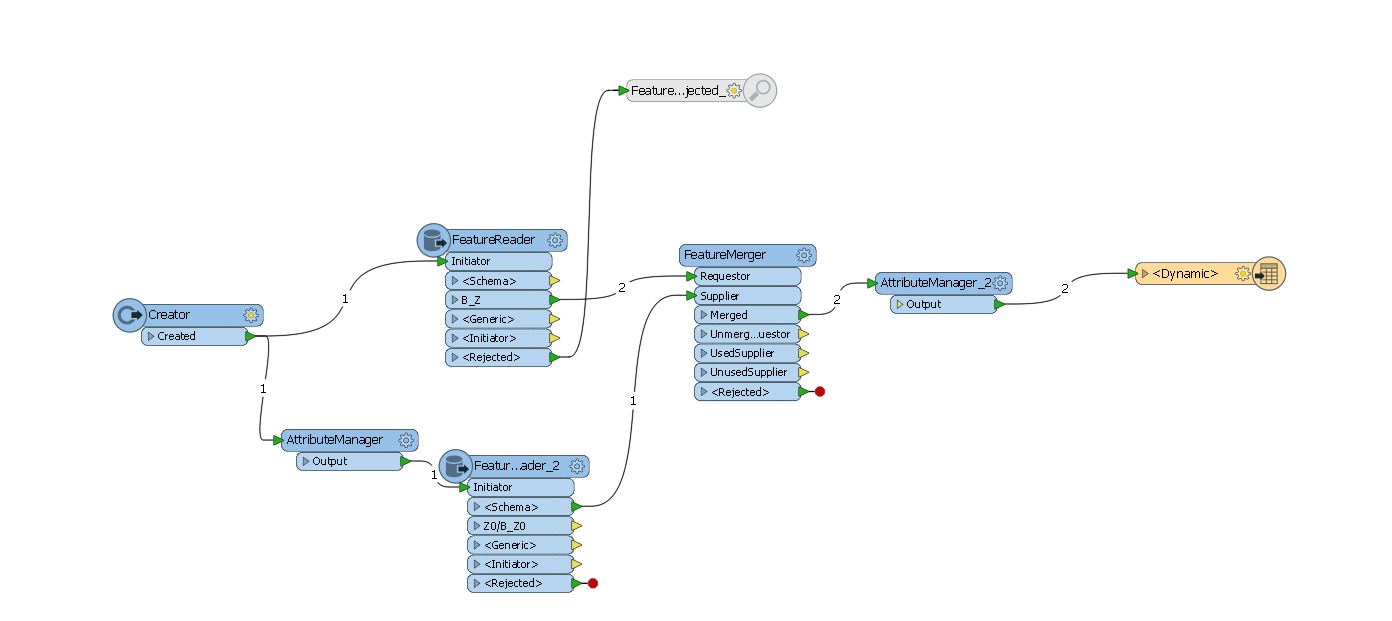
I have manage to export shp in file geodatabase with datasets but now it seems that i have a strange problem (or bug).
every shp that i have exported is missing 1st entry in geodatabase. lets say a shp file has 10 points then i’ll get only 9 points in gdb and the one is missing is always the 1st pont in shp file. every shp file is missing that 1st entry.
the strange thing is that fme shows in information that it wrote all entries that the shp files has but somehow 1 is missing.
there is absolutly no error in logs. i get some info about some fields that i don’t export anyway. i really have no idea why this is happening.
the shps are also exported with FME from othe types of data.
for writer i use Esri Geodatabase (File Geodb Open API) with some schemas that i read from a template database with featurereader and join it on shps (no schema was readed).
so what im doing wrong?
why there is no error about the missing entries?