
I am trying to email a file geodatabase. I quickly learned that FME Server doesnt like folders and will only zip and email files. So I went back to the desktop client and set the gdb to be zipped for output. Tested it on local storage and I get a valid zip archive that contains the gdb folder.
I then publish that workspace to FME Server and run it with a geodatabase folder parameter of
$(FME_SHAREDRESOURCE_DATA)\\BuildingFootprintQC\\BFP_overlaps.zip\\BFP_overlaps.gdb
OR
$(FME_SHAREDRESOURCE_DATA)\\BuildingFootprintQC\\
Neither works. The workspace runs without error but generates no output. I logged into the host server and checked the resources folders to make sure the zip is not there and indeed its not being created.
How can I get FME Server to follow the desktop function of zipping the output so I can tell the email action in the automation to send the gdb as an attachment?
Edit:
I checked the log and the entry MULTIREADER: output will be zipped only appears when running on the desktop client. In Server that entry is missing as if it doesnt honor the zip output function





 Here is an example.
Here is an example.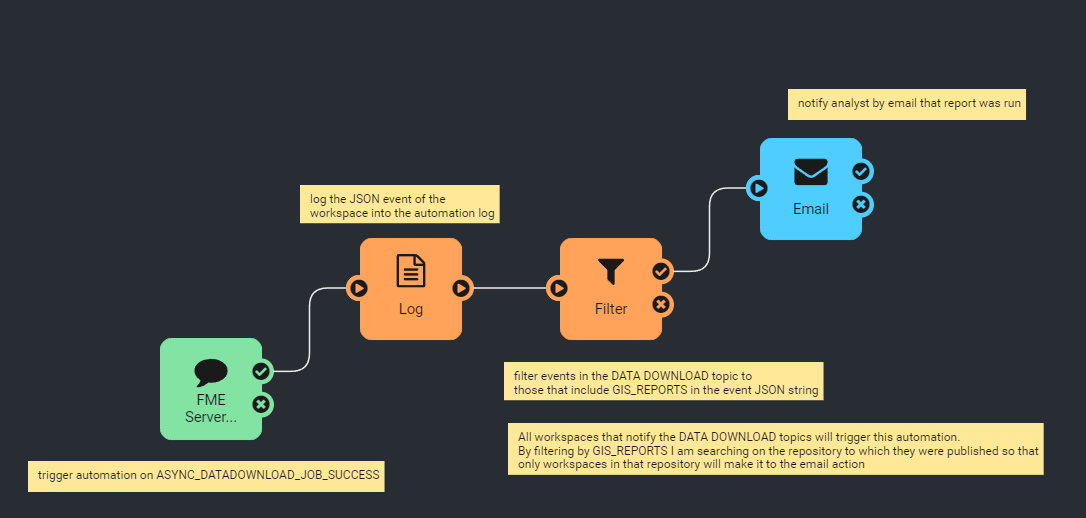 In this example the automation is triggered by posts to the ASYNC_DATADOWNLOAD_JOB_SUCCESS topic. The log action logs the entire job event as JSON so I can filter on the job information. I then filter by searching for a specific repository because im only interested in receiving emails from our reporting workspaces. Then the automation sends an email containing relevant attachments or information.
In this example the automation is triggered by posts to the ASYNC_DATADOWNLOAD_JOB_SUCCESS topic. The log action logs the entire job event as JSON so I can filter on the job information. I then filter by searching for a specific repository because im only interested in receiving emails from our reporting workspaces. Then the automation sends an email containing relevant attachments or information.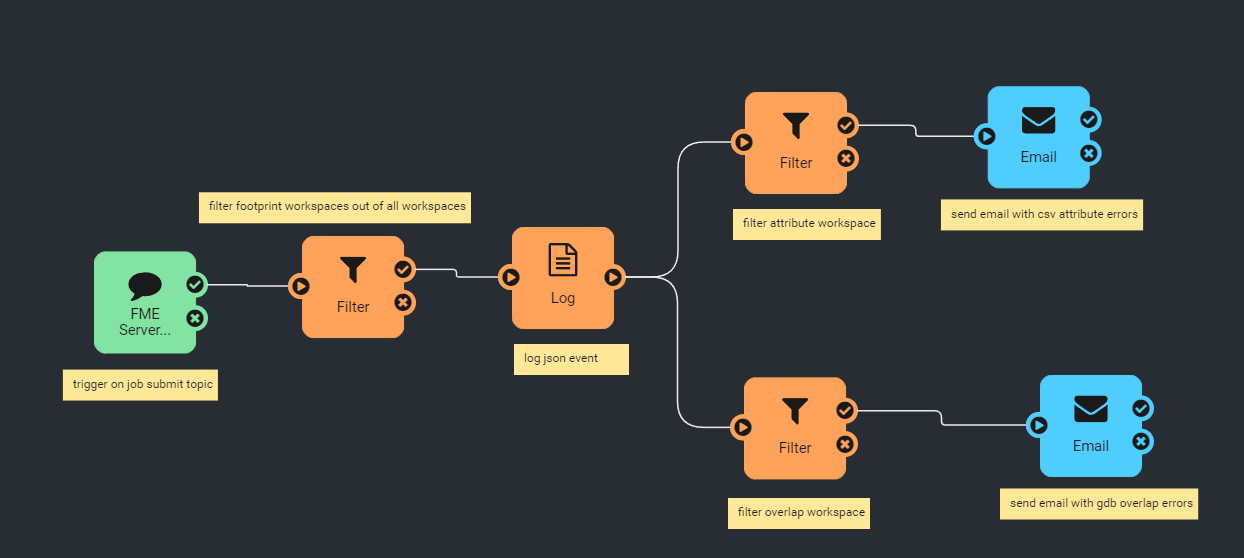 This automation is triggered by posts to the ASYNC_JOB_SUBMITTER_SUCCESS or ASYNC_JOB_SUBMITTER_FAILURE. It then filters the events by searching for "BuildingFootprint" which isolates the workspaces I want to focus on. It creates a log event of the full JSON for further filtering. It then splits the flow depending on which of the workspaces triggered the automation. If its the attribute check I did it takes the top path. If its the geometry validation workspace it follows the bottom path.
This automation is triggered by posts to the ASYNC_JOB_SUBMITTER_SUCCESS or ASYNC_JOB_SUBMITTER_FAILURE. It then filters the events by searching for "BuildingFootprint" which isolates the workspaces I want to focus on. It creates a log event of the full JSON for further filtering. It then splits the flow depending on which of the workspaces triggered the automation. If its the attribute check I did it takes the top path. If its the geometry validation workspace it follows the bottom path. To change the notification handling of all the workspaces involved i can modify 1 automation vs modifying and republishing every workspace.
To change the notification handling of all the workspaces involved i can modify 1 automation vs modifying and republishing every workspace.