


Happy new year, FMEers.
Our question-of-the-week was posted just a few hours before I started to review the week. It's about parallel processing and the ShortestPathFinder transformer.
Question of the WeekQ) I was hoping to speed up my ShortestPathFinder calculations with "Parallel Processing", but I don't notice any speed improvements. The 2018.1 documentation says "If it is enabled, a process will be launched for each group specified by the Group By parameter." However, the most recent documentation does not mention parallel processing at all. Am I missing something?
Asked here by @magnus
A) Yes, there are a number of points. The first is what happened to parallel processing in 2019, the second is how to ensure parallel processing works...
Parallel Processing in 2019
So here's a quick refresher on parallel processing in 2019. Basically it was removed from individual transformers and retained only in custom transformers. I wrote a blog article to explain why.
In short, parallel processing is an obvious tool for improving performance, but we felt that sometimes new users could – in attempting to speed up their translations – actually slow them down.
That’s why we moved the parallel processing parameter to a place where it’s naturally better performing.
Parallel Processing "Gotchas"In general, even when you have parallel processing set up, there are a couple of issues that can catch you out, as we say.
In short, if you have either Feature Caching turned on or Breakpoints activated, then parallel processing won't work. It's a technical limitation and in 2020 we have improved logging to be clearer that nothing is going on in parallel.
Parallel Processing in the ShortestPathFinderThe ShortestPathFinder searches through a network (usually roads) looking for the shortest route between two points. These two points are defined as a FROM-TO line. There can be multiple FROM-TO lines in your processing.
What's interesting is that each FROM-TO line is processed against the same network. You don't usually need to provide a new network for each FROM-TO process.
At least, that's true unless you set a Group-By value! If you set a group-by value then each group of FROM-TO lines must have its own separate set of network features with the same group ID. Because parallel processing requires a Group-By, you'll definitely need to create a set of network features for each process.
So What's The Matter Here?In this case the user might just have Feature Caching turned on, which stops parallel processing from taking place. In that scenario, turning Feature Caching off will ensure parallel processing occurs.
But I think the big issue is that parallel processing only works with groups, and groups + ShortestPathFinder can be fairly slow because if a Group-By is set, then there needs to be a separate set of network features per group.
This is what I do here:
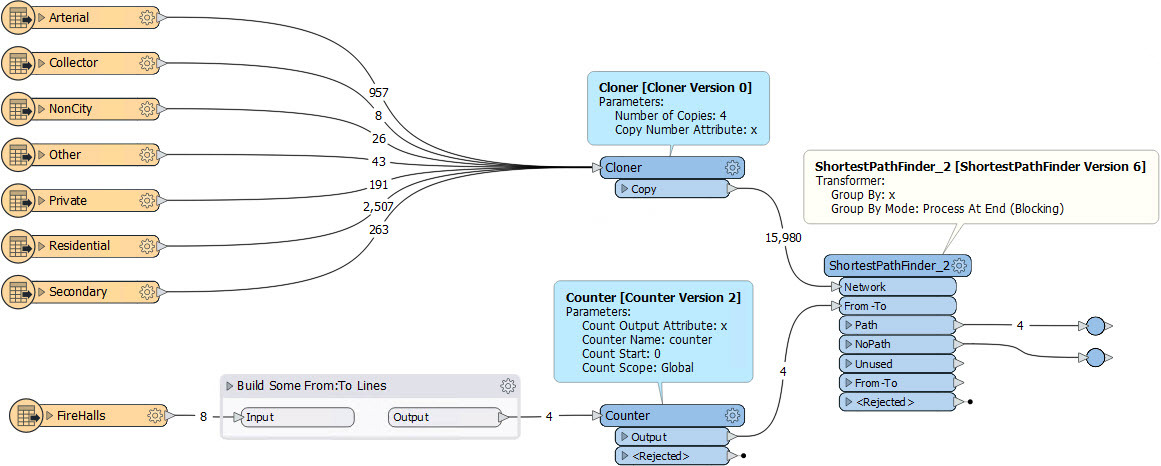
Notice that I clone the network the same number of times as I have From-To lines. There is a common ID between each line and its network (x), so I group by x.
The user could do the same, and turn on parallel processing (or put it into a Custom Transformer for parallel processing in 2019). This will work fine... except there is a snag!
The user reports: "The input is about 7 million from-to-lines"!
OK, so 7 million lines is a lot, and we really don't want to be cloning the network 7 million times. So what do we do?! We put the Network data reader into a separate workspace with the ShortestPathFinder and run that once for each From-To line using a WorkspaceRunner transformer:
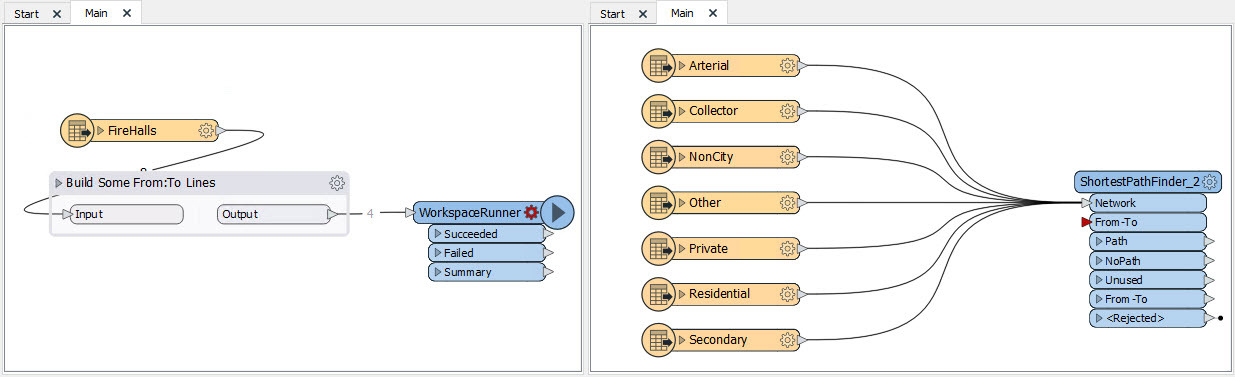
The problem is, how do we get the From-To line into the next workspace? It merely starts the process; it doesn't get passed through as a feature.
So... we'll save the line's geometry and pass it through as a published parameter. Now my workspaces look like this:
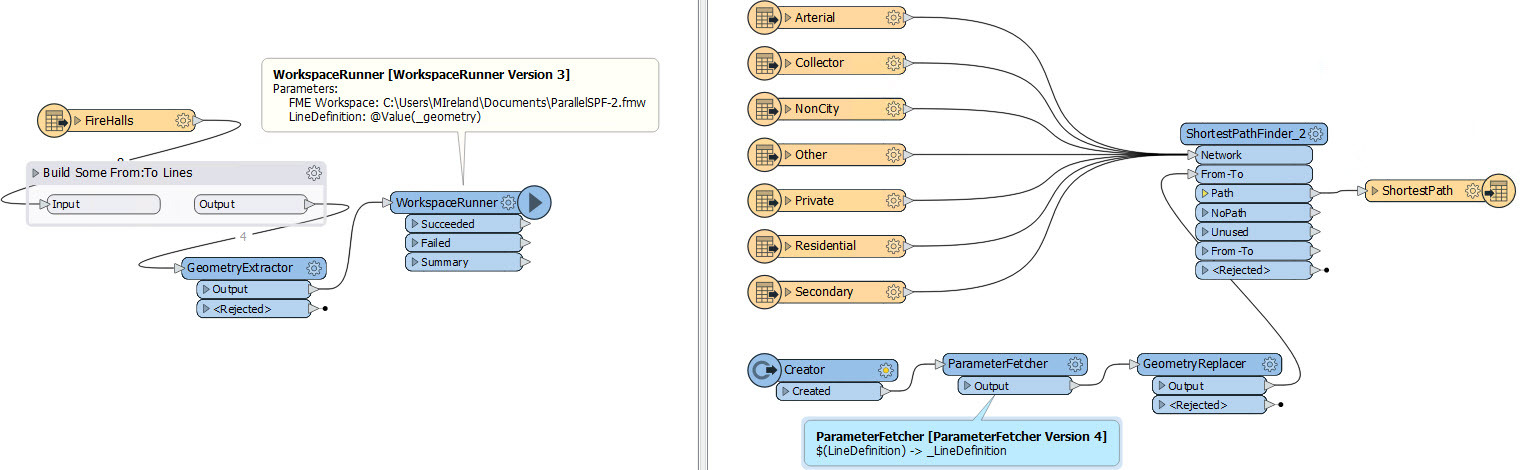
I fan-out the FFS writer in the second workspace, using DateTimeNow() in the file name so it doesn't overwrite the previous result (as described in a previous question-of-the-week), and then run the workspace. The results:
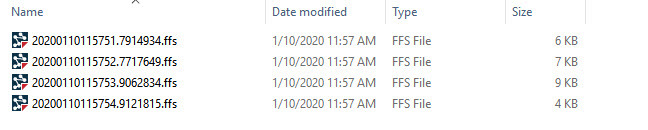
Four routes, each written to a separate output. I could write them to the same output dataset, but only if I could append to it (like a database) and not always overwrite (like a file-based format).
The final part: set up the WorkspaceRunner to run multiple processes in parallel. So, in my case I would set up the transformer to run a maximum of four processes:
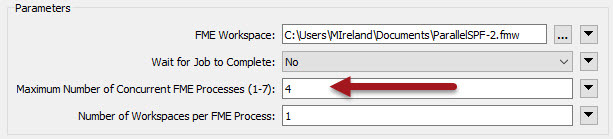
On the other hand, the user in this question had 7 million features and an 8 core system. So they would run 8 processes. But setting the Workspaces Per Process parameter (also described in a previous blog) they can make sure only 8 processes are ever started at a max:
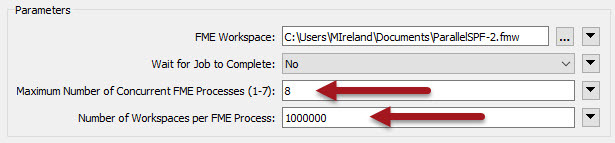
We set Number of Workspaces to 1 million, because I'm rounding off and saying 8 million features divided by 8 processes is 1 million actions per process.
The only concern I have here is applying 1 million workspaces per process might cause excess memory usage. In that case reduce the number of workspaces per process if things get a bit slow.
SummaryPhew! That got lengthier than I expected. In short, when you divide data into groups to parallel process, you need to duplicate the road network. Do that 7 million times in a single workspace and it will be very slow, regardless of parallel processing.
So, we move the reading of the network into the separate process. We're still reading that network 7 million times, but not all at the same time, which is the key.
The result is we don't actually use "parallel processing" in a single workspace, we run the process as a bunch of workspaces in parallel.
The Process Monitor on your computer is a great way to check how many processes are running, and how much memory they are taking up.
I hope this is useful. If it's still slow, please let us/me know. I do like how I managed to incorporate two previous blog entries and a question-of-the-week into my answer. I like to think it shows how important my work is! ;-)
Other Notable QuestionsJust a few other questions of note this week:
- Batch Execute Eight Workspaces in Parallel on FME Desktop
- @ashitosh asks the question and it is sort of similar to the above. The problem is that they are trying to run workspaces as they are called by the user; i.e. they aren't known in advance as above. It needs a sort of queueing mechanism and really that's the sort of thing where FME Server is what's needed. Unfortunately budget limitations might preclude that, which is a shame because it could take a lot of work to replicate the functionality already in Server.
- Set Python Interpreter for a Workspace
- @tomrosmann asks how to set a different interpreter for each workspace. My colleague @chrisatsafe supplies an answer, but I think there's a bit more to it. Chris and I discussed this earlier today. The Python Compatibility parameter doesn't really set the Python interpreter as such, it merely suggests to FME which interpreter to use based on version. If you tell it your workspace is compatible with Python v3.5, FME will use Python v3.7 because that's the latest and it is compatible with v3.5. Having said that, it should be OK for this user, because ArcGIS and FME python interpreters are treated as incompatible; so if the default interpreter is set to FME v3.6, but compatibility is ArcGIS 3.6, then FME will look for an ArcGIS interpreter. It won't try and use the FME one, even if the version number is compatible. It's quite a confusing issue but an interesting one. Ask me below if you need more info.
- What are the Default Coordinate Order Conventions in FME
- An interesting question from @thijsknapen about whether coordinates are lat/long or long/lat in FME. Well, FME works on the relatively standard X = longitude, Y = latitude, and you can assume that is the case in any transformer. Sometimes source data has it the other way around, but you hope that the data includes a flag (like it would in GML) to denote that. As long as FME can see a flag in the data, it will happily process the data correctly.
- Holiday Hackathon Results
- Again, a big thank you to all who took part in the Holiday Hackathon, whether entering a project, voting on a project, or just reading up about some of the interesting projects that were submitted.

")



