Hello FME'ers,
Because Friday is a holiday this week, you get the question-of-the-week post a little early. Hurrah for long weekends that start on the Friday. So much better than ending on a Monday, I think.
Question of the WeekThis question from @rmm7 came up yesterday and relates to testing and filtering data:
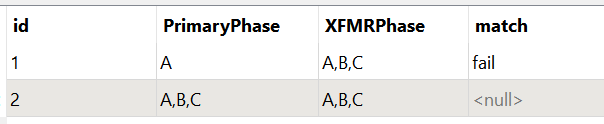
Q) I'm trying to match values between two attributes on the same feature.
I have an electric transformer with a phase value, and it's connected electric cable, also with a phase value. The phase values can be any combination of A,B, or C. For example, the electric transformer might have a value of AC, and the cable it's joined to has a value of ABC.
I'm trying to find a way to test if the phase values of the transformer are contained within the phase values of the cable.
A) This question got a number of answers, and I think the user has a way forward. But in working out my particular answer, I came up with an idea and thought I'd share it here, to see if it would be useful.
If you don't want to go through the whole thought process, then just skip to the Summary section, where I outline what that idea is.
Otherwise, let's start by looking at what exactly we're trying to do here...
Question Requirements
So there is an electric transformer and a cable. Each has a list of phase values. We need to know if the transformer values are stored within the cable values.
So, for example:
- Cable Phases: A,B,C
- Transformer Phases: A, C
- Result: Passed
But:
- Cable Phases: A,C
- Transformer Phases: B, C
- Result: Failed
In short, we need to match lists of values, and you can't really do that by default in the Tester.
ApproachesThere are two ways to approach a problem like this.
Firstly, we can go for a generic approach, where we try to solve the problem of list matching, without restriction. So the solution would work for any list, not just the examples here.
Secondly, we can go for a focused approach, where we try to solve the problem using the limits specified by the user. In this case, "the phase values can [only] be any combination of A,B, or C", plus from the examples shown, we can assume the values are always in alphabetical order.
This makes the task much easier because there are only a set number of matches.
By my calculations there can only be 7 different values (A/B/C/A,B/A,C/B,C/A,B,C). As @erik_jan points out, you can use the Tester with a CONTAINS operator, to eliminate most of those matches. Only A,C is difficult because it's the only possibility not contained within the full A,B,C string.
So something like this:
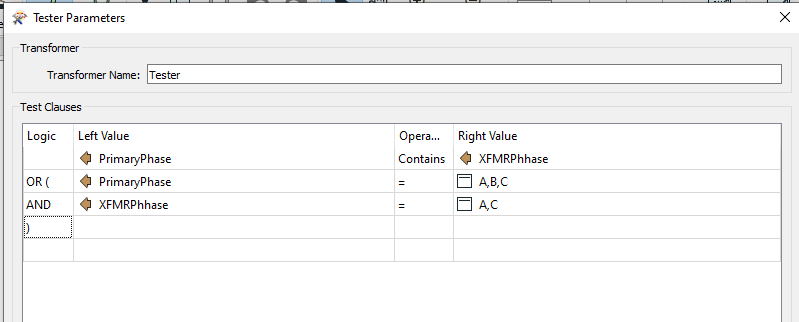
...should be fine. Great reasoning and a nice answer there Erik.
So why is my question title banging on about Lists and the InlineQuerier?
A Generic Approach using ListsPersonally, I started out looking for a generic approach to the problem. I often do that because you can end up with a solution that works for many scenarios - not just this specific question - and then you can put it on the hub and other users can find it
Plus, the generic approach often turns out to be the same as the focused approach, so it doesn't matter anyway.
Here the core problem is this:
Problem: It's not easy to test multiple values in one string, against multiple values in another string.
OK, if we can't test the values in that structure, can we restructure them to something easier? If you've got comma-separated values (like A,B,C) the simplest transformation is to put them into an FME List attribute.
So I add two AttributeSplitters:
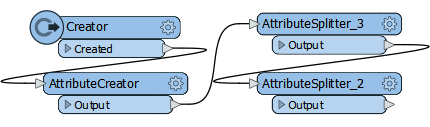
And now I have list attributes, phaseList1{} and phaseList2{}, say like this:
phaseList1{0} = A
phaseList1{1} = B
phaseList1{2} = C
phaseList2{0} = A
phaseList2{1} = CProblem: It's not much more easy to test multiple values in one list, against multiple values in another list.
What I'd probably do here is create a custom transformer and check all the values in phaseList2{}, looking for their equivalent in phaseList1{}. I'd need a custom transformer loop, with a ListSearcher transformer to do the actual testing.
But custom transformers and loops seems a bit complicated for this. Is there a better way? What else could we restructure the data to?
A Generic Approach using RegexMy next idea was to use Regex and this is the solution I posted to the question. @ebygomm came up with a Regex solution too.
My version was:
@FindRegEx(@Value(PrimaryPhase),(?=.*@Value(xList{0}))(?=.*@Value(xList{1}))(?=.*@Value(xList{2}))) != -1Her's was:
@FindRegEx(@Value(PrimaryPhase),@ReplaceString(@ReplaceRegEx(@Value(XFMRPhase),([A-Z]),(?=.*\1)),",",""))As @redgeographics says, creating Regex on the fly must be the ultimate FME hack. To be fair I think both solutions are quite horrific! Mine was mostly a cut-and-paste job from StackOverflow and is not fully generic. Plus, I'd hate to be an FME user and have to come up with one of these.
So what else do we have?
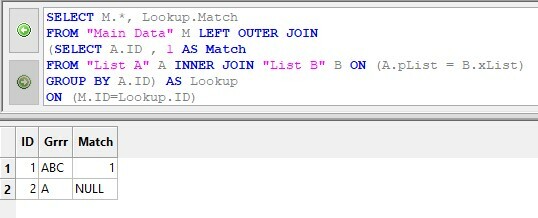
A Generic Approach using SQLCould we use SQL? Why not? It has the advantage of a single line of "code" and it would be fairly readable too, not some Regex gibberish.
But how do I get the attributes into a database and what do I use to query them? I'd need to have several tables all joined together with keys, and how do I set that up?
I use a single transformer: the InlineQuerier:
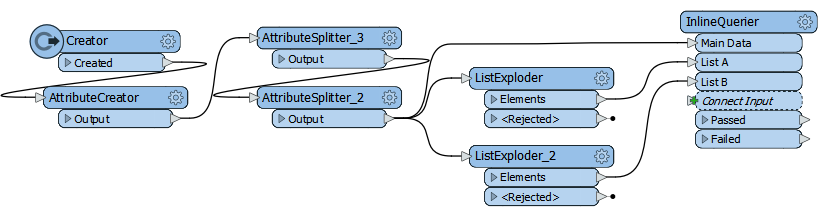
This is the million dollar idea I wanted to share!
If I just route the data into an InlineQuerier as a single connection, I'm no better off. A List is a List, and the transformer won't automatically process that list into a more usable table.
But if I explode the list and send it as a separate connection to the InlineQuerier?
Now I have a scenario where I can build a single SQL query to pick features where all entries in List B join with an entry in List A.
Problem: My SQL skills have gone rusty over the years because I've rarely needed to use them.
That's a problem with me, not the technique. I think the technique is sound, it's just that I can't figure out how to structure the SQL. So far I have:
select distinct "ID" from "List B" where (select count(*) from "List B" where "xList" in (select "pList" from "List A")) = (select count(*) from "Main Data" as m join "List B" as lb on m.ID = lb.ID)Yikes! It works, but only for one feature, and it looks pretty sad. Maybe someone with better SQL skills can come up with a better command?
But still, using SQL has opened up a lot of possibilities here.
SummaryOverall, I think this is an interesting question and all, and it does show us the different approaches we can take towards solving a particular need.
But what I really wanted to pass on was the idea of exploding a list and sending it into an InlineQuerier as a separate input.
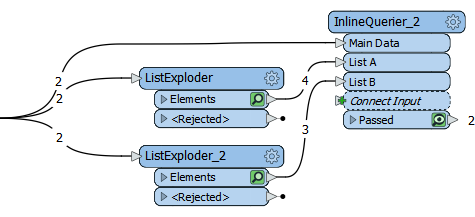
Here I have two lists, so I split them off, keeping the original stream in case I need it. This way I get multiple database tables, automatically, and can run a query that combines all elements of them.
It even lets me query between previous/subsequent features, without using the Adjacent Feature processing.
When I think of all the transformations I've tried to do on a list, it seems to me that they could be much easier using SQL. It's half way between putting multiple transformers together and writing a Python script to do the job. As most new FME users know more SQL than FME transformers, I think it could help.
I don't know if this is a truly unique idea, or whether you've been doing this already. Maybe you think it's a dumb idea? Maybe you think that we should put an option into the InlineQuerier to explode lists like this? Either way, it's OK. This just popped into my head and so I wanted to pass it on in case it was of use.
Let me know below what you think.