
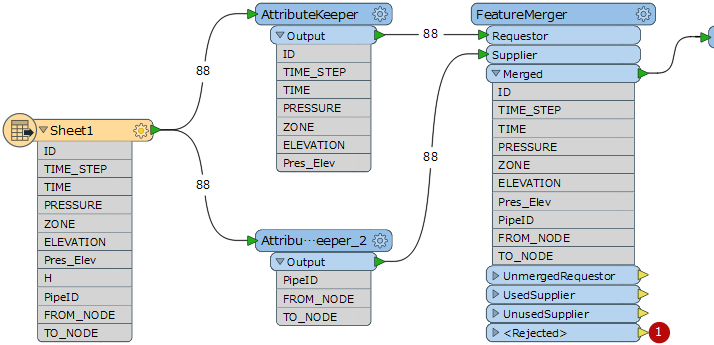
I have two sets of tables in an excel sheet. I want to pick each element from one column of one of the tables and try to find a match in another column of the other table. As soon as I find a match, I want to merge the corresponding rows. I was trying to use FeatureMerger but wasn't able to perform the task. Could you please help me out? Thank you

Solved
ms excel data manipulation
Best answer by fmelizard
Hi @rhlkochar, the FME 2018.0 beta currently available (build 18165) has the ability to read in Excel tables similar to Excel sheets. You can specify to read in the tables as different Feature Types which will allow you to perform the merge using the FeatureMerger.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.










Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.