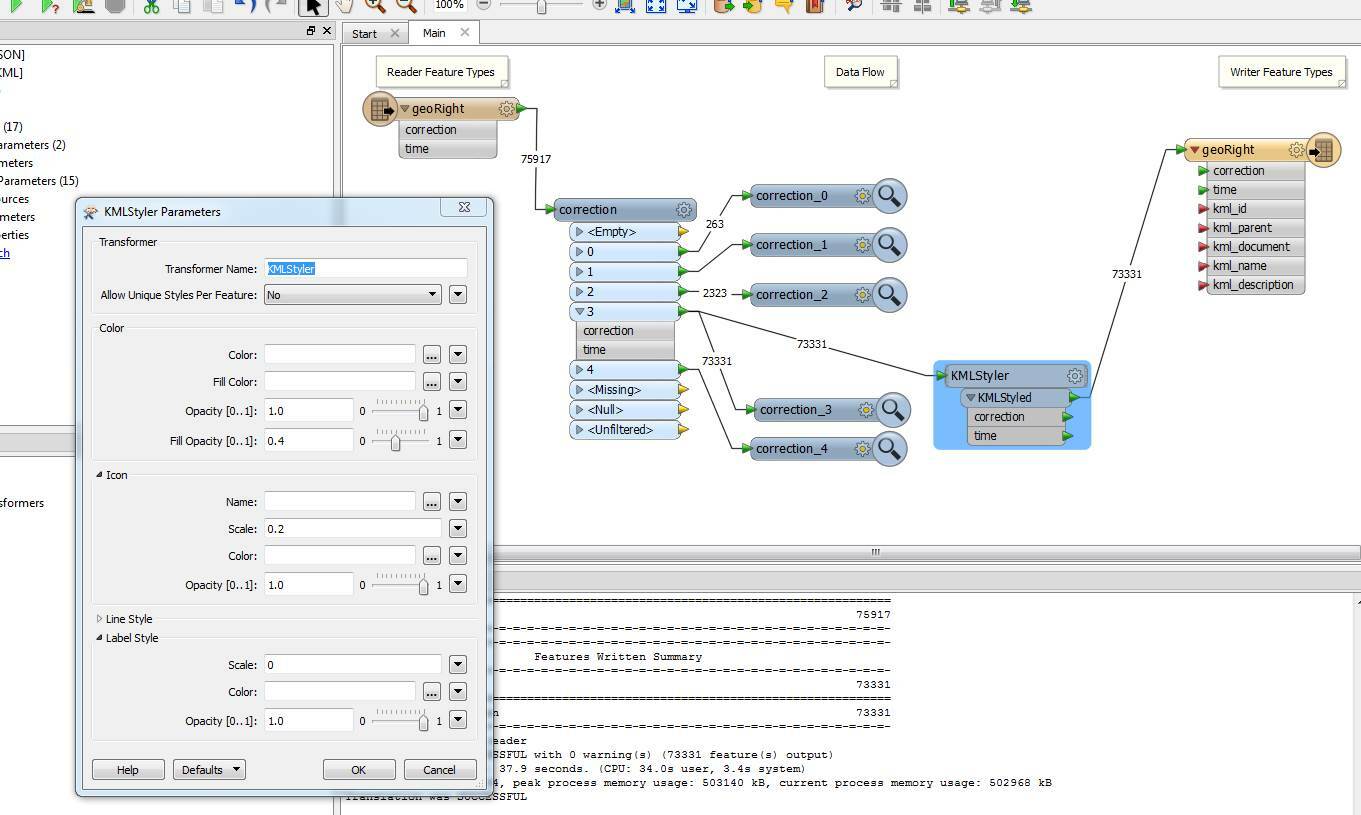
Yes, that is a lot. But let's see if I can do this before I start using FME to subsample. I would love to see it all overlaid on a google earth map.
I figured out how to hide the Label, and make the icon smaller, but I really want this to be just a one or four pixel icon for each point, and any other tips you can give me to make Google Earth render faster.