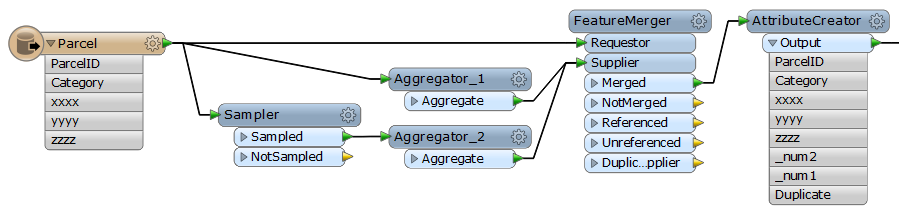
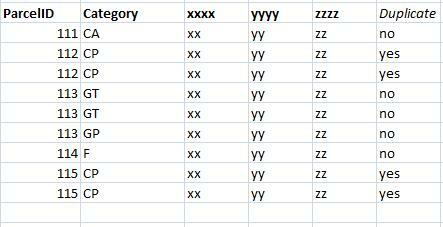
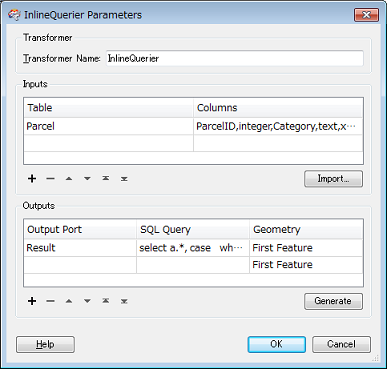
I have x features (many millions but im running a testset of 20k) and they all have an Parcel number. Each feature has an associated Category (one of eight) that is made up of 1 to 3 letters.
Now, each parcel number does not necessarily occur just once; there could be up to 9 instances of each parcel number and each instance may, or may not, have the same Category code.
I wanted to test the Category attribute - grouped by Parcel - to see if there was a complete set of Category duplicates ('Yes') or if the Category differed at all ('No') for a given parcel.
(Bonus qu: In some cases where there are 6 instances of a Parcel and there are 3 different categories, it is clear to see that the 3 different categories have been duplicated by mistake - because there are associated identical areas - does anyone know how to clean those out??)
thanks all