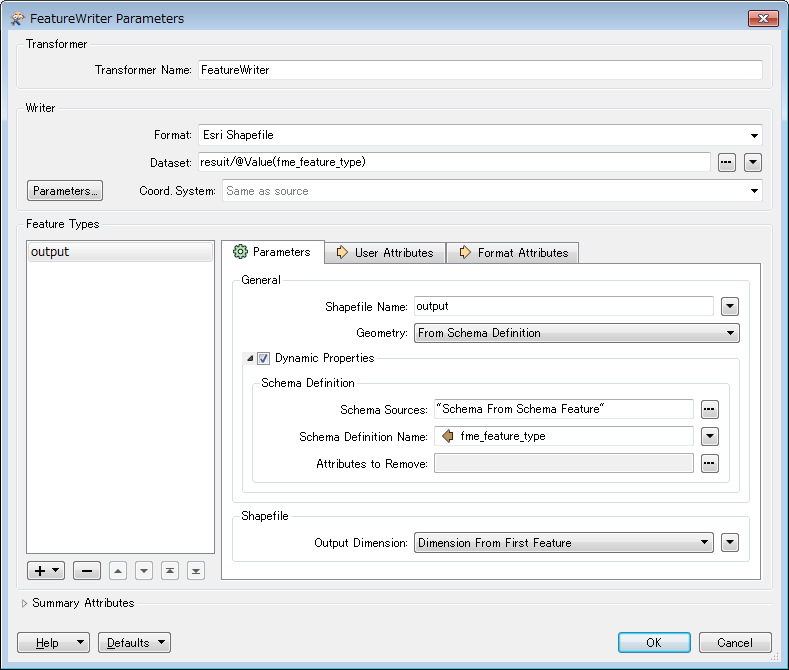
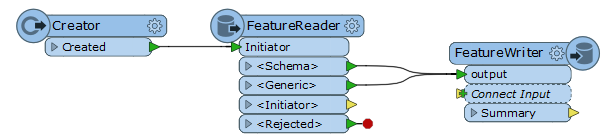
Hello,
FME 2017.1.1.1 build 17652, 2017.1.2 beta build 17717, 2018.0 beta build 18208
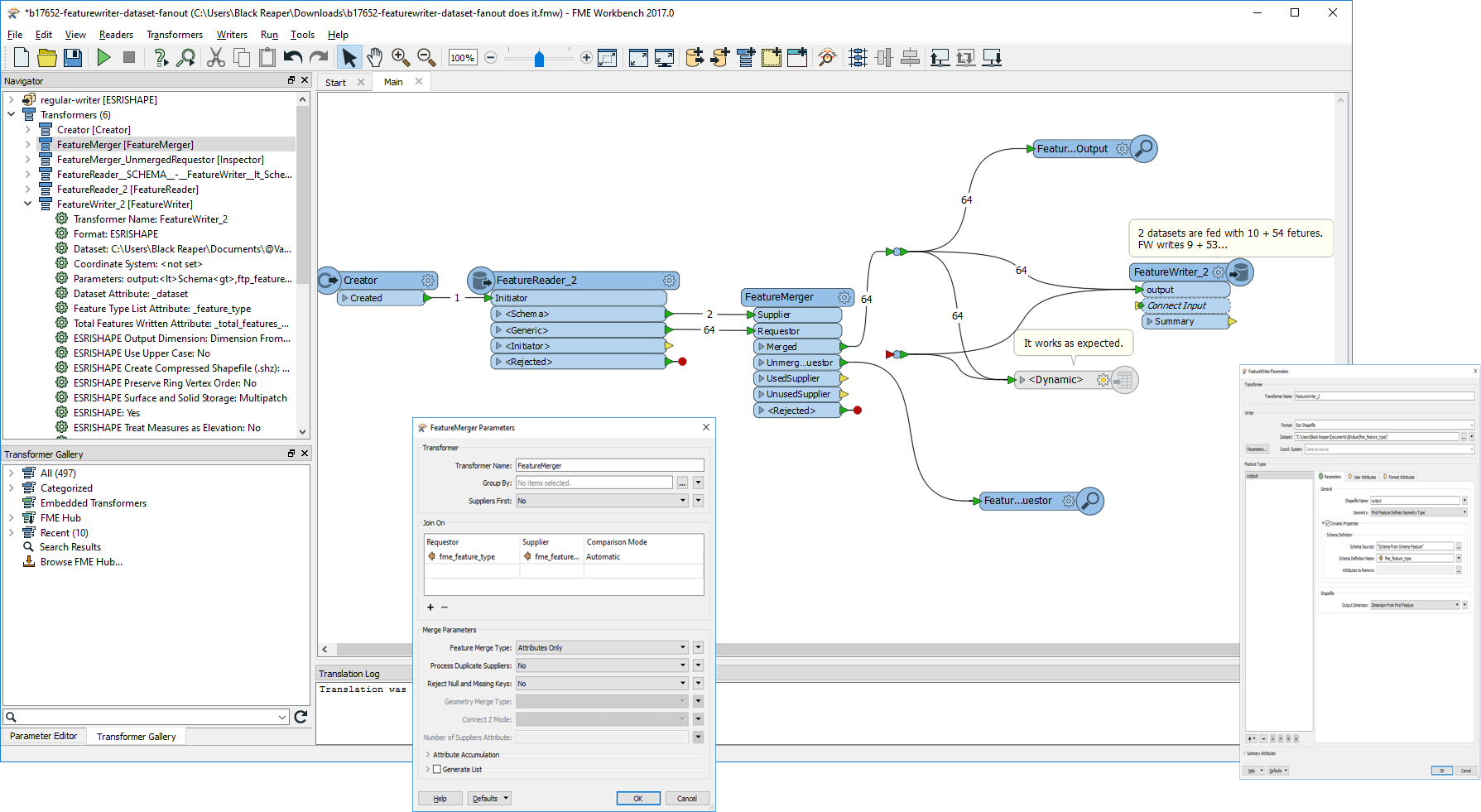
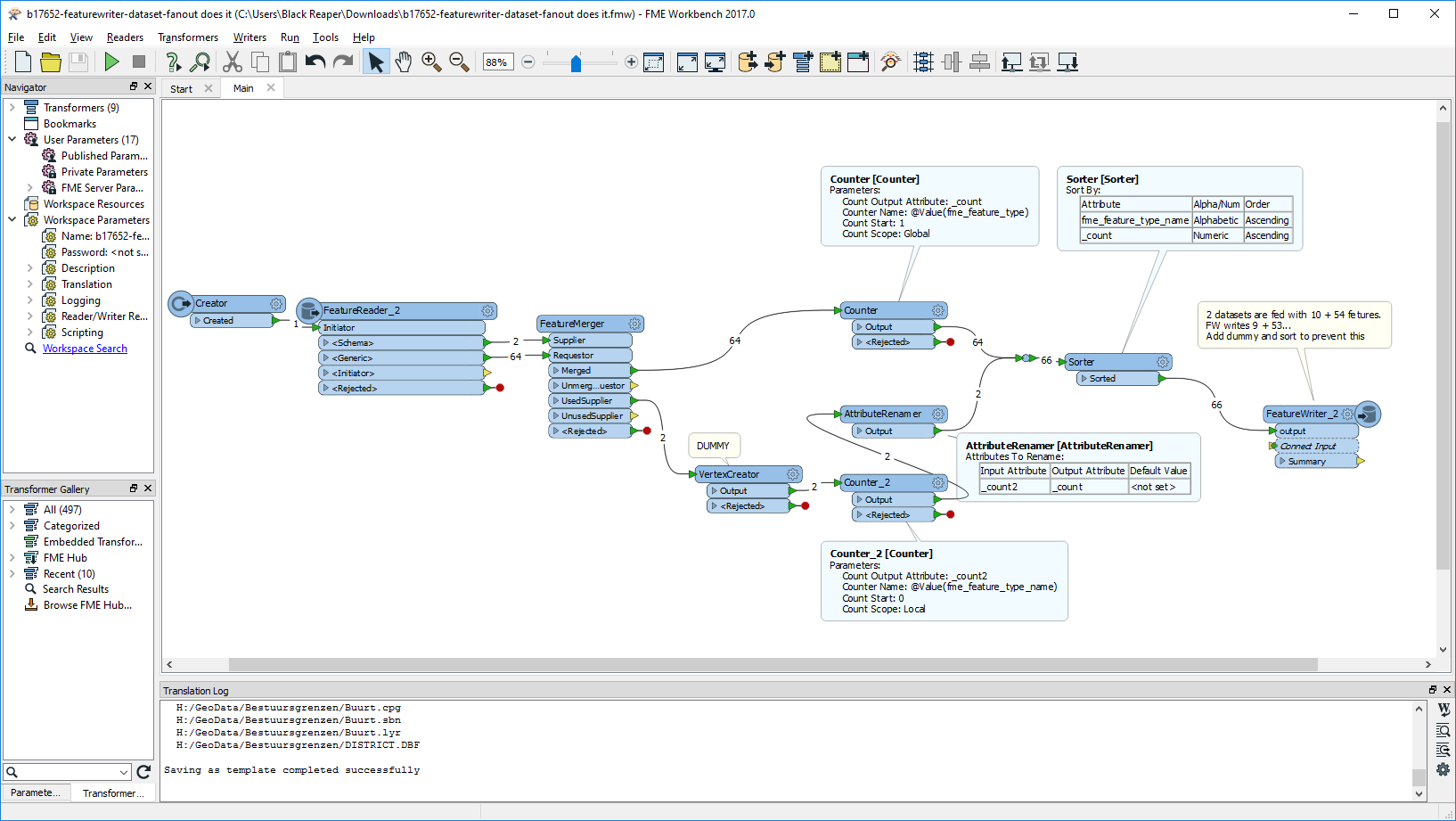
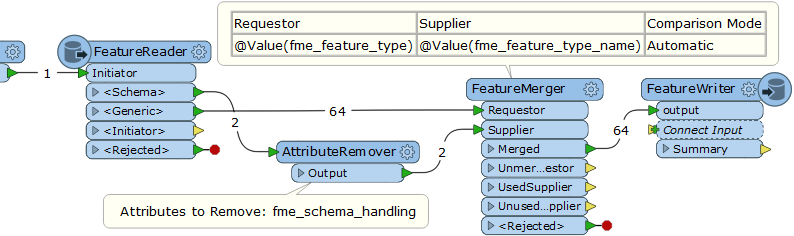
The scenario is:- The source dataset contains multiple feature types. e.g. "A", "B", and "C".
- Read every feature from the source dataset and simply write them into Shapefile files for each feature type separately, with the same schema as corresponding source feature type.
- Here, the destination dataset (folder) names should be the same names as the source feature types. i.e. "A", "B", and "C".
- And all the destination files (feature types) should have an identical name. e.g. "output.shp"
- In fact, the names and schema of source feature types are unknown when creating the workspace, so you want to configure Dynamic Schema and Dataset Fanout.
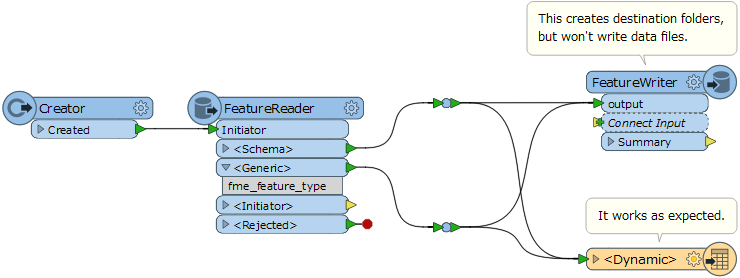
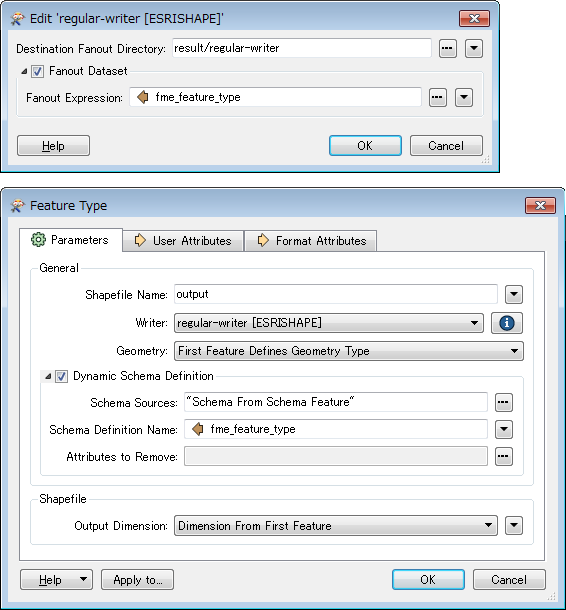
Feature Writer Parameters:
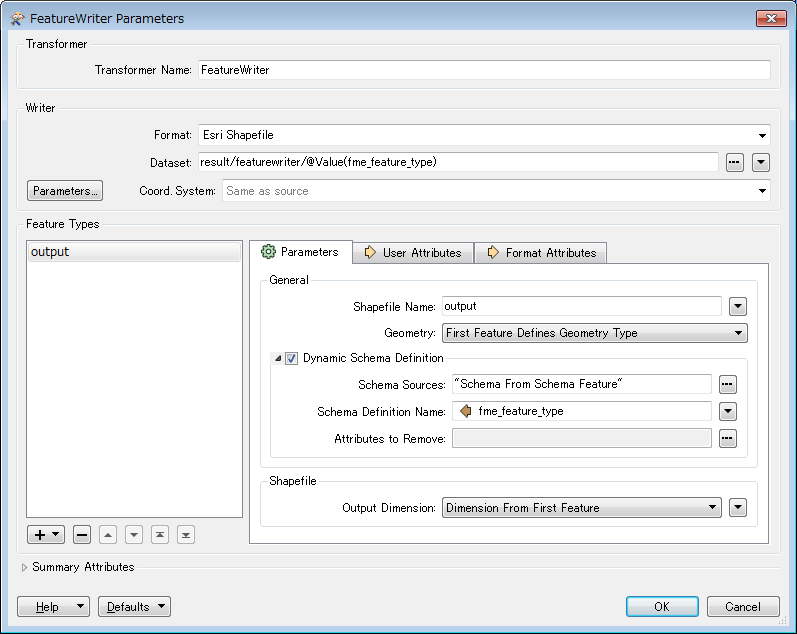
Shapefile Writer Configuration: