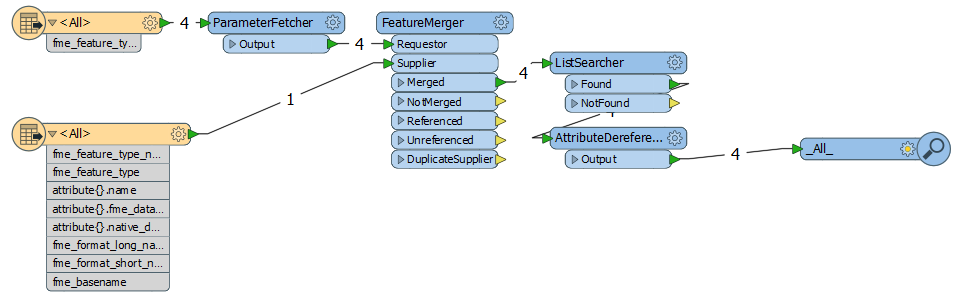
Hi,
is it possible to define the reader attribute names via commandline or via an external file?
I have excelsheets where the column name is different e.g. somtimes they are called FMEA, von_km etc. The excel sheet is uploaded by users on a website. On the website they specify the worksheetname and the column name how they are called in their excel file.
An other problem is that the they are not always in the same collumn position.
Thank you for your help.