Hi all,
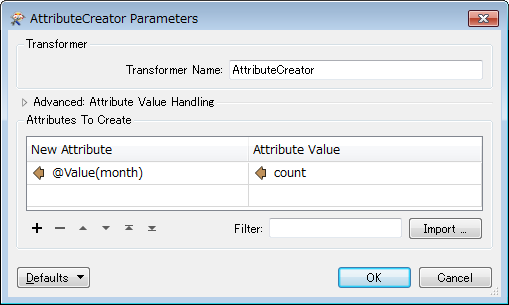
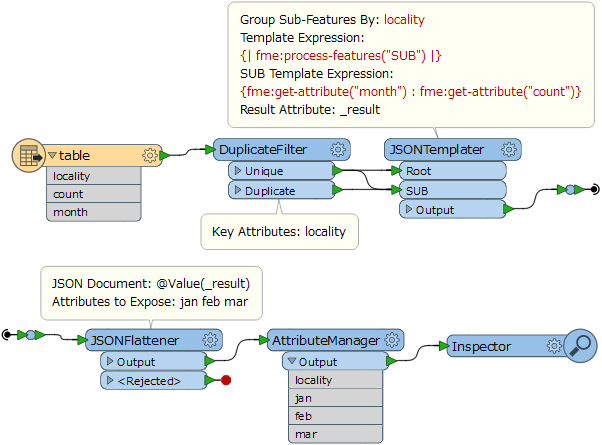
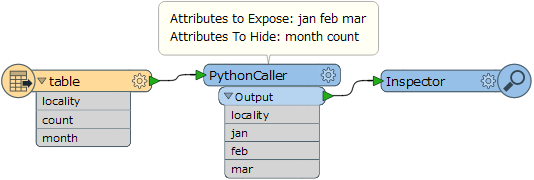
I have an attribute table in the following format:
localitycountmonthbright123janbright456febbright789marmyrtleford987janmyrtleford654febmyrtleford321marI would like to change it to the following format:
localityjanfebmarbright123456789myrtleford987654321I have a convoluted process using an attribute filter and a bunch of statistics calculators but it's not very scaleable. I was wondering if anyone can point me in the right direction for an improved solution!
Cheers,
Barrett