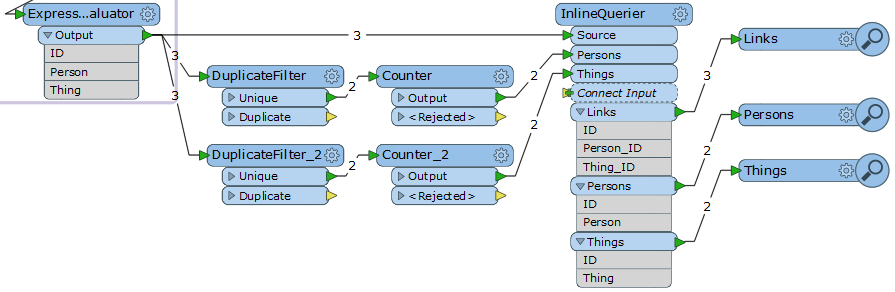
Hi.
What is the best way to generate values for new numeric identy fields in Redshift which not exist in source structure of tables and bind this new values with other data?
For example there is table
IDPERSONTHING1JhonCar2AdamCar3JhonPenI want to split this table into three tables:
1) PESRONS
IDPERSON1Jhon2Adam2) THINGS
IDTHING1Car2Pen3) LINKS
IDPERSON_IDTHING_ID111221312So, I need to negerate ID for tables PESRONS and THINGS, and bind persons and things by this new identities in table LINKS.
How I can do that in FME desktop?
Thanks.


")