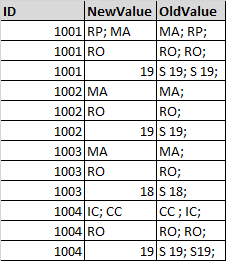
I have created a sample table below of a much larger dataset.
I want to be able to group each ID and then be able to compare the New and Old Values to see if they are the same, in some cases the order is wrong, or there is a semi colon and space or there are duplicates. How do I clean all this out, so that I can make a more accurate comparison of the two columns?
Best answer by takashi
Once you have split the semicolon-separated values at semicolon and stored the individual values into a list attribute using an AttributeSplitter (Trim Whitespace: Both, Drop Empty Parts: Yes), you can sort the elements with the ListSorter and remove duplicates with the ListDuplicateRemover. Finally you can re-concatenate the elements into a string in semicolon-separated format using the ListConcatenator.
Once you have split the semicolon-separated values at semicolon and stored the individual values into a list attribute using an AttributeSplitter (Trim Whitespace: Both, Drop Empty Parts: Yes), you can sort the elements with the ListSorter and remove duplicates with the ListDuplicateRemover. Finally you can re-concatenate the elements into a string in semicolon-separated format using the ListConcatenator.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.