Hi
So I have a text document and I need to parse into specific headings and then extract that heading and all the sub text. The issue is the subtext is lettered. Is there a regex syntax that will continue to extraxt until it finds a new match? any ideas?
Im using string searcher and have managed to get all this data as seperate lines, just not sure if its easier to try and find a way to put the data back together or if theres a more efficient way to parse
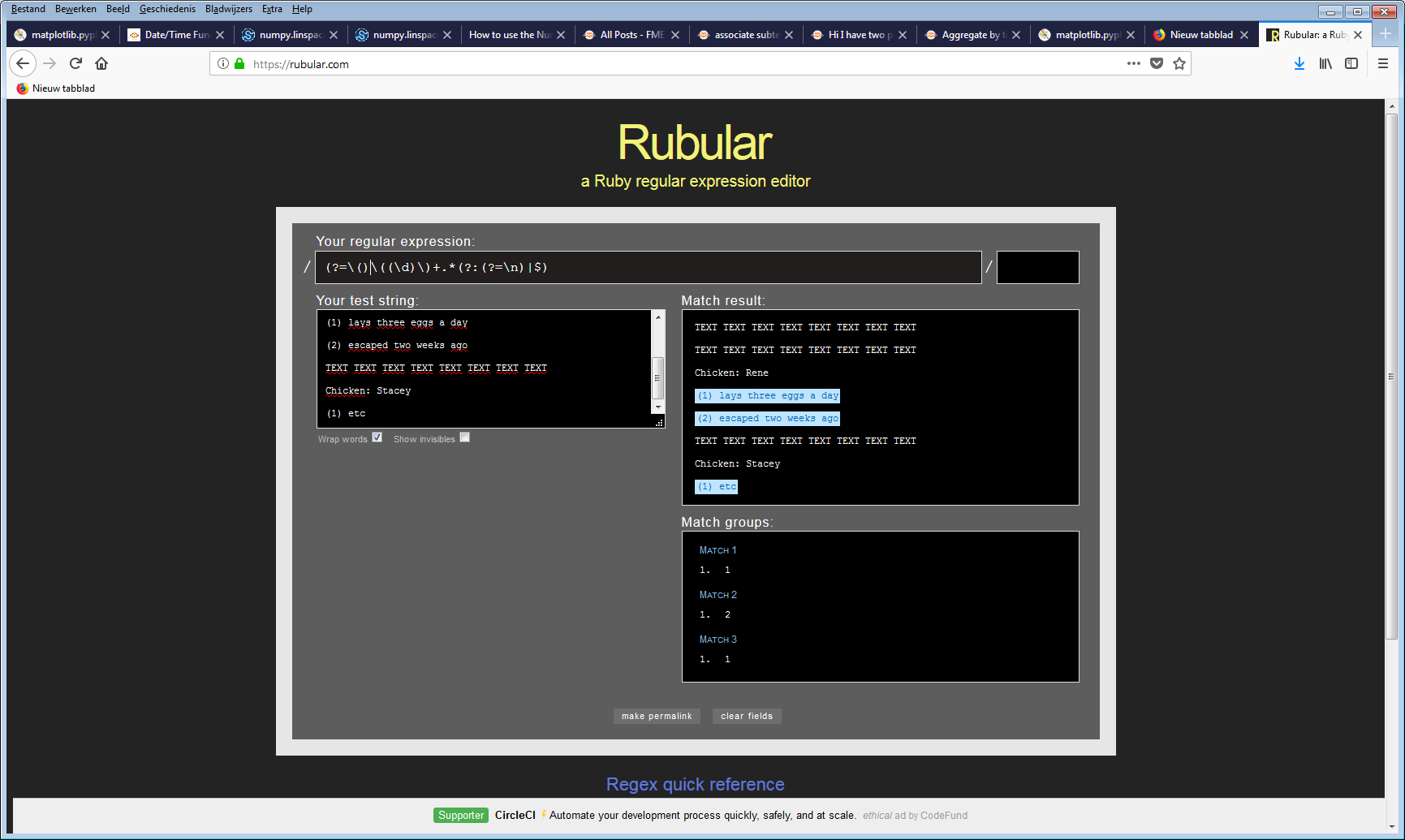
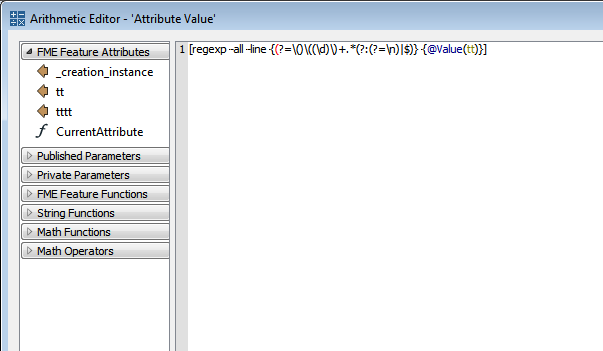
Current using syntax: chicken{1}\\s|(.
Example: I need every line that starts with "chicken" the chickens name and all the numbered lines below
TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT
TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT
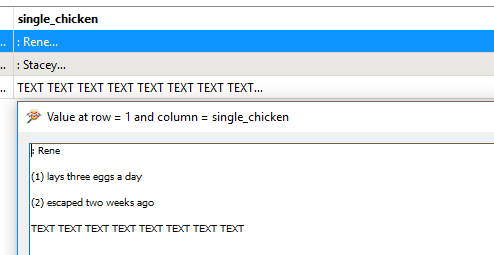
Chicken: Rene
(1) lays three eggs a day
(2) escaped two weeks ago
TEXT TEXT TEXT TEXT TEXT TEXT TEXT TEXT
Chicken: Stacey
(1) etc
and so on