Good afternoon all,
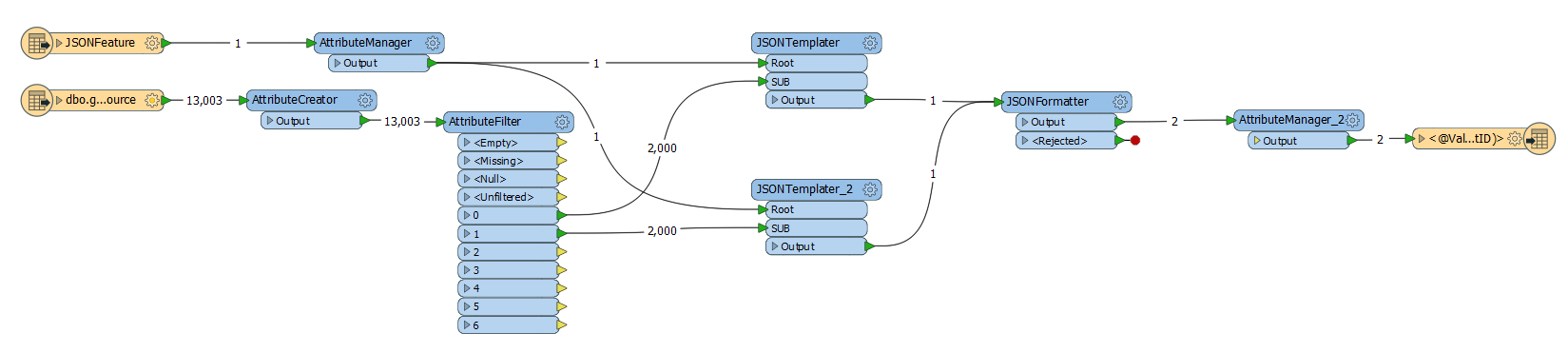
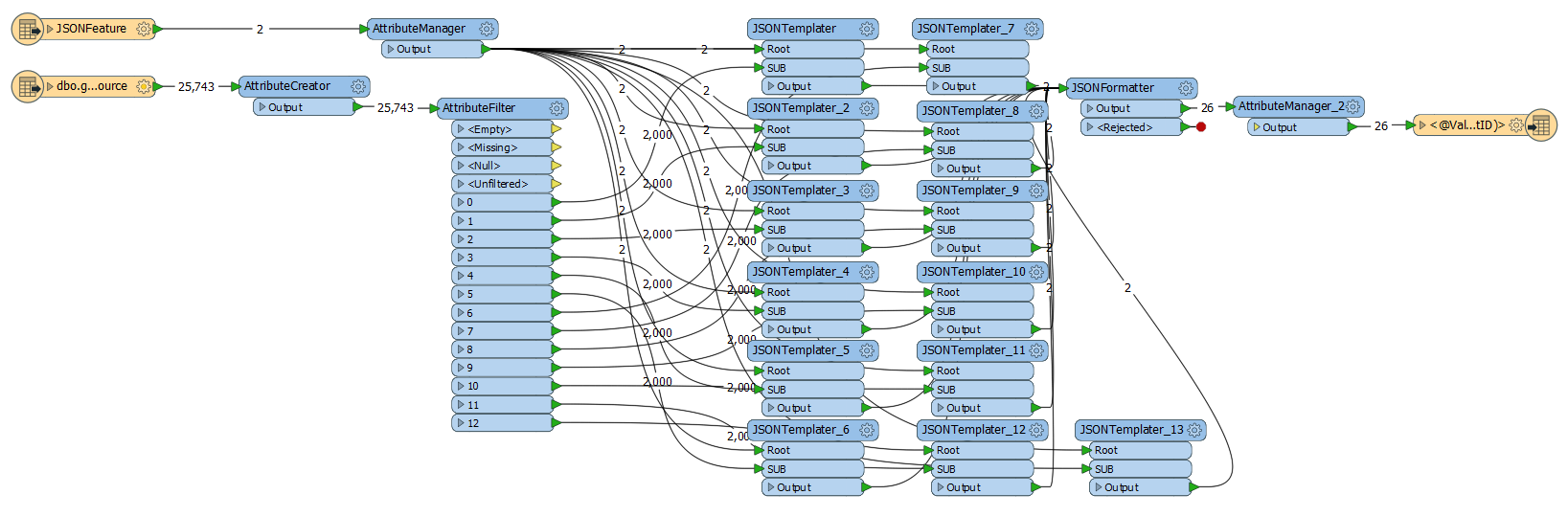
I'm trying to create a large nested JSON document from SQL to load into MongoDB. Currently I have managed to create the JSON file but i'm not able to load it into Mongo based on the size of the documents. The maximum size for documents is 16MB while my average document size is over 50MB.
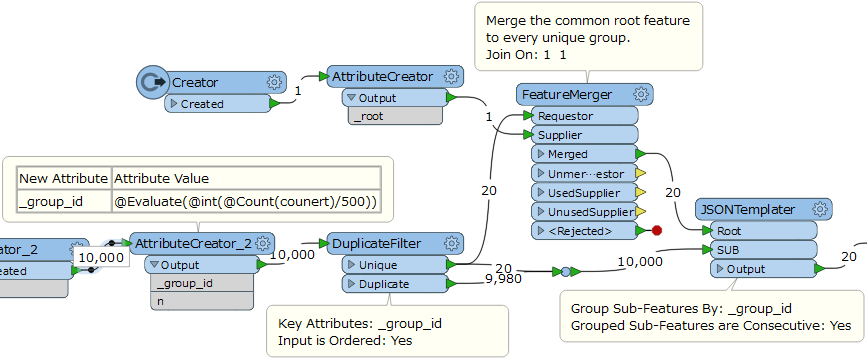
A solution I have thought of is to bucket each of the sub files so that instead of thousands of documents being embedded into each root there is a maximum limit of say 500 and then a new document is created with the same root, but a continuation of the Sub documents. In the end instead of a single 50MB document I would be left with say 10 identical documents that would hold different Sub documents from one another. I could then query the set of 10 documents using $unwind so that it treated them as a single document of sorts.
Does anyone know of a way to achieve this within FME Workbench instead of loading all sub documents into a root?