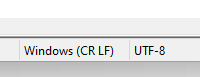
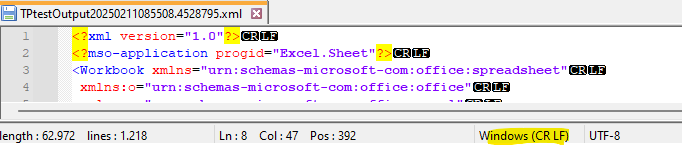
I have been given an xml file which when opened in Notepad++ shows encoding “Windows (CR LF)” “UTF-8”
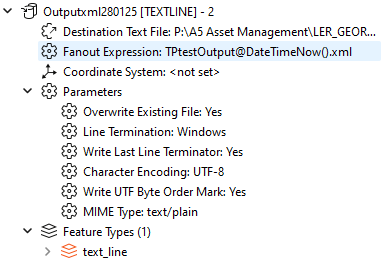
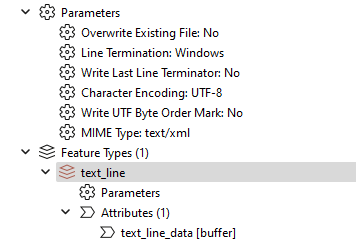
I need to write a new file with the same encoding. My writer has these parameters
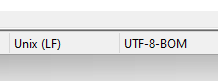
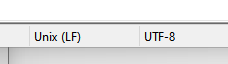
It writes the file ok but in Notepad++ the file encoding shows “Unix (LF)” UTF-8-BOM”
What writer parameters should I use to get the same output?
Best answer by eric_armitage
I found a solution. Add a python caller before the text writer with this code. It replaces every unix EOL in the XML with Windows EOL. (LF to CR LF)
import fmeobjects def FeatureProcessor(feature): text = feature.getAttribute('text_line_data') text = feature.setAttribute('text_line_data', text.replace("\n", "\r\n")) return text
Without Pythoncaller
With Pythoncaller
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
If you don’t have the Byte Order Mark then set Write UTF Byte Order Mark to No.
Are you writing a single xml feature to the text line writer? I think the Line Termination setting only comes into play if you are writing multiple features to a text file line by line. You’ll have to control the line terminations used when forming the xml (or check whether it actually matters for your use case)
If you don’t have the Byte Order Mark then set Write UTF Byte Order Mark to No.
Are you writing a single xml feature to the text line writer? I think the Line Termination setting only comes into play if you are writing multiple features to a text file line by line. You’ll have to control the line terminations used when forming the xml (or check whether it actually matters for your use case)
Hi thanks for that. I’m writing a single XML feature. Switching the byte order mark to no fixes the encoding but still can’t get the file to output as Windows. Even though the writer is set to Windows it always comes out as Unix. These are by current writer parmaters.
As I said, the line termination parameter won’t make an impact if you are writing a single feature, as it controls the line termination between each feature sent to the writer. How is the xml being constructed in your workflow?
As I said, the line termination parameter won’t make an impact if you are writing a single feature, as it controls the line termination between each feature sent to the writer. How is the xml being constructed in your workflow?
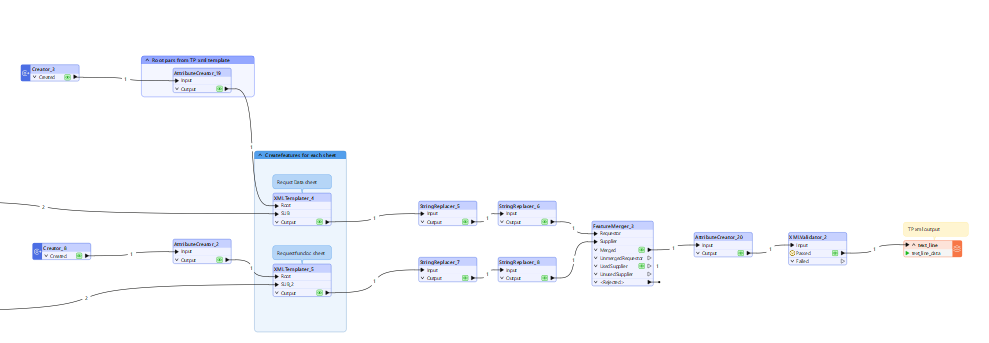
The xml is constructed using a series of xml templaters then merging the results into a single text_line_data attribute of type xml.
I think for Notepad++ to see it as CR LF on open you will need to ensure the line terminations are CRLF in the xml. But I don’t think it should actually matter as line feeds would normally be stripped out when xml is parsed
I think for Notepad++ to see it as CR LF on open you will need to ensure the line terminations are CRLF in the xml. But I don’t think it should actually matter as line feeds would normally be stripped out when xml is parsed
I have tried running it through an XML Formatter with different formatting options but nothing seems to work. Still comes out as Unix (LF)
You’ve got Overwrite existing file set to No. That means FME will append to your file, which probably means you now have a mixture of LF’s in there. You might want to check if that helps.
Alternatively you can try to see if the XMLFormatter makes a difference. With that one you can even linearize your xml, so there won’t be any CR;LF;’s in there anymore.
You’ve got Overwrite existing file set to No. That means FME will append to your file, which probably means you now have a mixture of LF’s in there. You might want to check if that helps.
Alternatively you can try to see if the XMLFormatter makes a difference. With that one you can even linearize your xml, so there won’t be any CR;LF;’s in there anymore.
The file name uses “date time now” so it always creates a new file with a different name rather than overwriting. I tried linerize setting. It does then write as Windows. But then the format is invalid in the system im trying to upload the file to.
I found a solution. Add a python caller before the text writer with this code. It replaces every unix EOL in the XML with Windows EOL. (LF to CR LF)
import fmeobjects def FeatureProcessor(feature): text = feature.getAttribute('text_line_data') text = feature.setAttribute('text_line_data', text.replace("\n", "\r\n")) return text