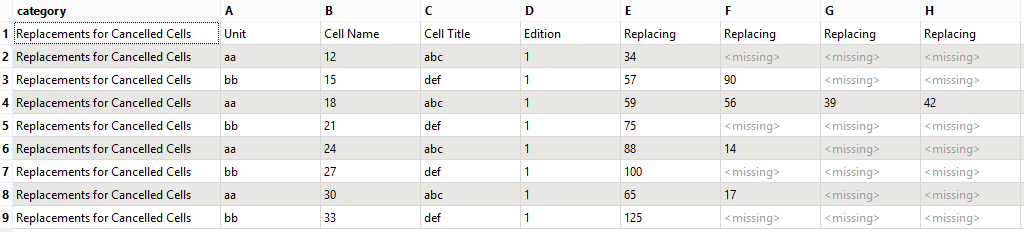
Hello, I would like to delete the first record/row of my table and use its values as the attribute names instead, e.g. I would like to call the second attribute "Unit" instead of "A". I can't specify that the first row is the header when I'm reading the file because I need to do some modifications in FME before the renaming. Which transformer/s should I use?
Secondly I would like to delete columns F-H by multiplying row 3, 4, 6 and 8. The aim is to have only one column that is called "Replacing".
Thank you for your help!