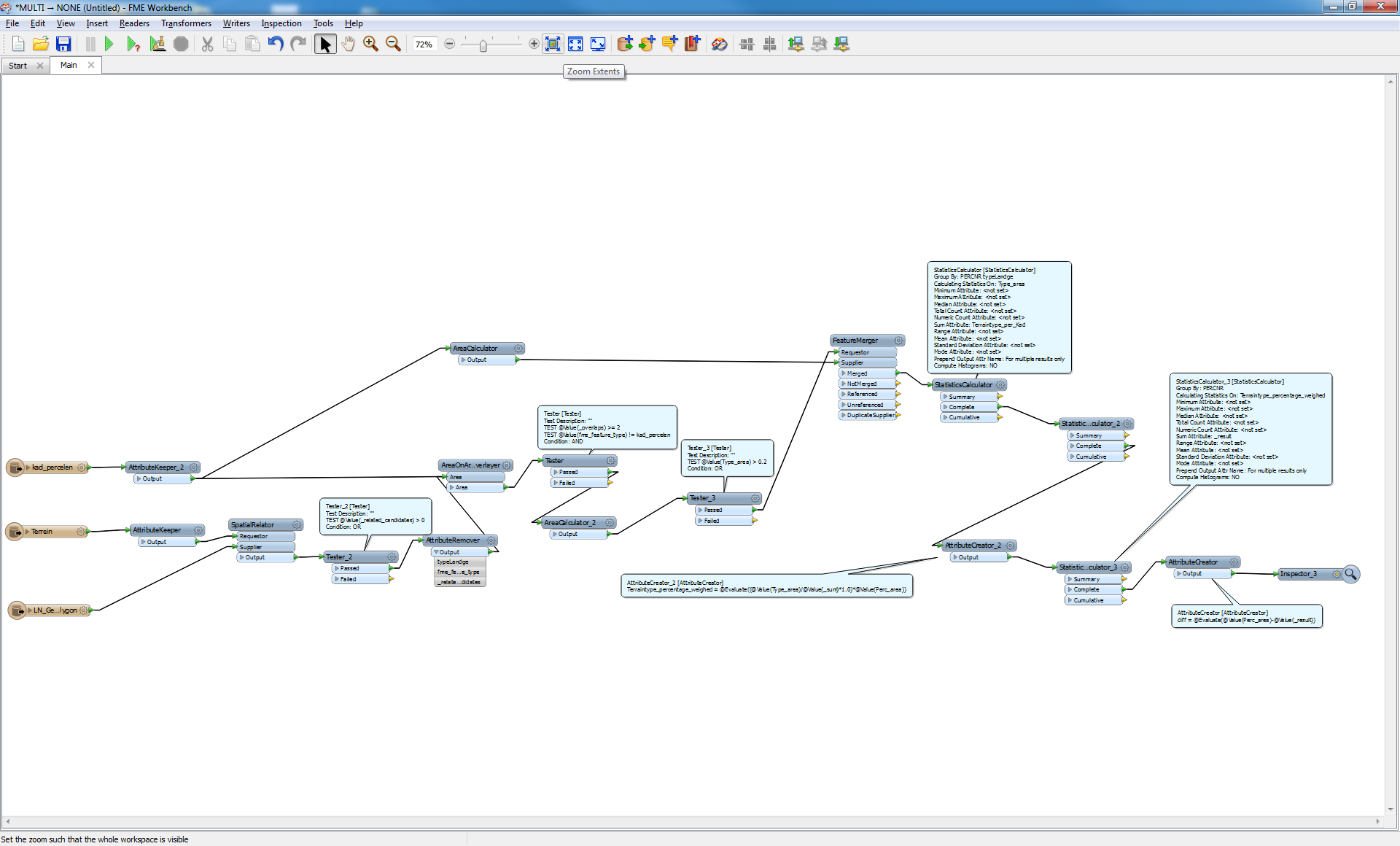
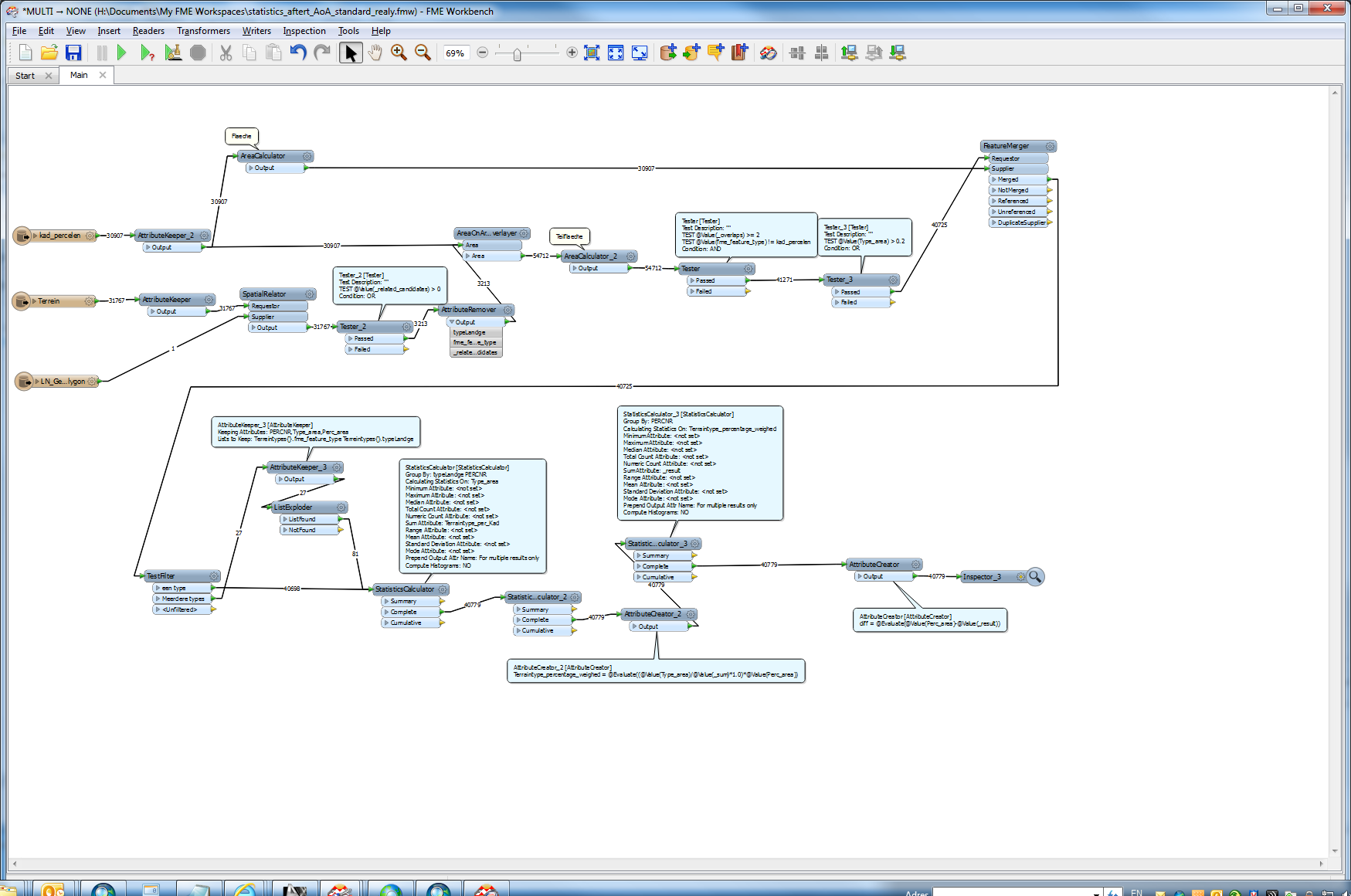
I have created an FME workspace for processing cadastral data that does it's job. However, it is rather slow and takes several days to complete. I want to briefly explain what the workspace does. Perhaps somebody here has an idea on how to optimize the workspace further.
It consists of a total of 5 polygonal datasets. The first one represents cadastral parcels. The others are dataset of the type of use, for example areas of living, areas of traffic and areas of economic usage. The datasets all overlap, but the boundaries of the type of use need't to be equivalent to the cadastral parcels, which means they can be smaler or overlap. The goal is to calulate for each cadastral parcel the areas for all overlaping type of use. The sum of these areas must not be bigger or smaler then the offical area of the parcels.
For example:
One parcel has an offical total area of 1000 square metres (sqm). It has three overlapping types of use with an real (GIS) area of:
A) Traffic: 205 sqm
B) Living: 499 sqm
C) Economic: 303 sqm
The first task is to calculate which type of use there are on a specific parcel. For that I use the AreaOnAreaOverlayer (AoA), with a list for the use types. This list is then "exploded" to features, so that for each parcel a new feature for the type of use is created.
The second task is to adjust the areas of the types of use. In the example above, the sum of the areas must be exactly 1000 to match the parcel. Since I do not know how many types of use are in one parcel (list), I use several ExpressionEvaluators. Before that, I split the features with a TestFilter in dependance on the number of types of use per parcel. All this is static, so if there are for example ten types of use per parcel possible, there have be at least ten groups of ExpressionEvaluators transformers.
It it's of any interest I will upload the workspace. But perhaps somebody has an idea on how to optimize it, especially the time consuming part with the AreaOnAreaOverlayer.
Parallel processing wasn't of any help, because it requires a group by parameter which is only present in the cadastral parcels dataset, not in the others.
Kind regards
Thomas