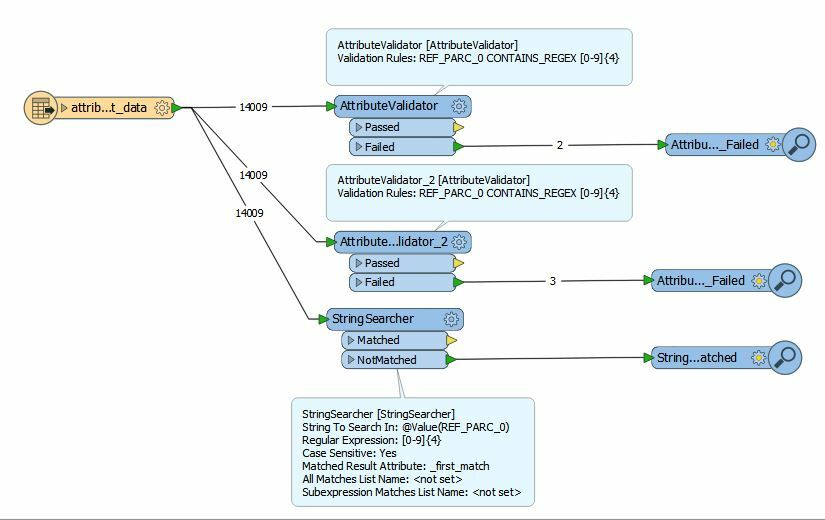
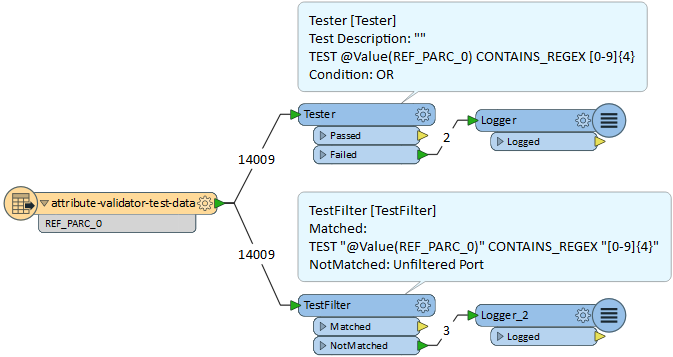
Not sure whether it's just because it's Friday afternoon and I'm missing something obvious but I'm seeing some strange behaviour with the attribute validator. Same input, same test, different results



 +51
+51Not sure whether it's just because it's Friday afternoon and I'm missing something obvious but I'm seeing some strange behaviour with the attribute validator. Same input, same test, different results
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.