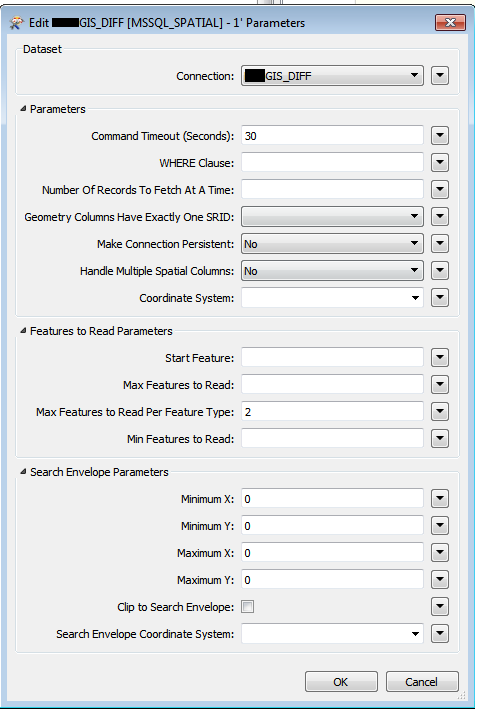
I have tried multiple combinations, but it seems the "Max Features to Read Per Feature Type" value is being ignored. I have 14 Feature Classes selected in my "FEATURE_TYPES" Published Parameter, so hence, if I set the value to 2, it should read 28 records but unfortunately it seems to only read 2 records from a random Feature Class.
I am using v2016.1.0.1
Refer @mhab's comments in this idea post: https://knowledge.safe.com/idea/25361/add-a-max-feature-to-read-per-feature-type-paramet.html
Best answer by markatsafe
View original