I have a bunch of workbenches running and one feature class in particular is acting very peculiar.
This data is simply being moved from one GDB to another, it is new data overwriting old data.
Today (for example) it is just five features, the first feature in the list will not overwrite, but the rest do.
I imported the first feature on it's own and it worked, I also tested it where I selected the tables in a different order, and that worked.
I then deleted the reader and created a new one, and the feature ran and was successful on the feature class. The second time I tested it, it didn't work.
This same thing happened on a different workbench with the same feature list, that first one did not work.
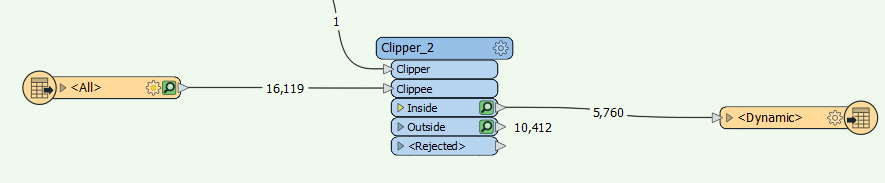
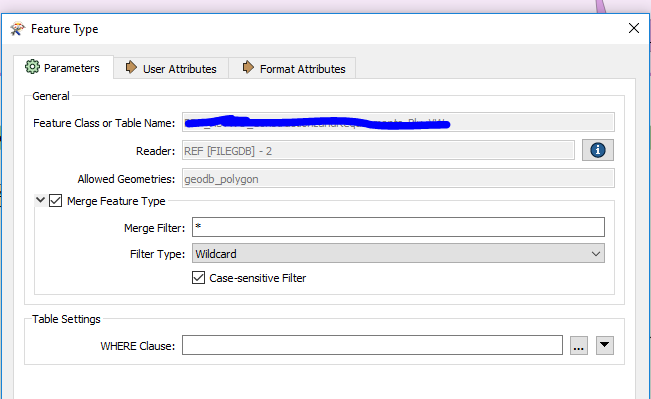
Any ideas why it won't work sometimes? The only thing that I see is it is the first in the list of the feature list I'm running and it is the only name that shows in the "Feature Class or Table Name" in the transformer (see second image below), even though it's running the entire list as a single merged feature.
Hopefully that makes sense?