Hello!
I'm trying to parse JSON data returned from the API for Oracle Service Cloud. I've figured out the HTTPcaller piece and the data is returned like this:
{
"count" : 10000,
"name" : "OpenData REST export",
"columnNames" : [ "Address", "Channel", "Date Closed", "Date Created", "Date Last Updated", "Disposition ID", "Latitude", "Longitude", "Product Hierarchy", "Product ID", "Service Request ID", "Status Type" ],
"rows" : [
[ null, "Email", "'2018-06-20 12:46:36'", "'2018-06-19 17:36:19'", "'2019-08-20 18:22:39'", null, null, null, "Parking", "Valid monthly permit", "2296", "Solved" ],
[ null, "Email", "'2018-09-06 10:13:19'", "'2018-06-19 18:28:00'", "'2019-08-20 18:22:38'", null, null, null, "Parking", "Disputing information on offence", "2299", "Solved" ],
[ null, "Email", "'2018-06-28 14:45:50'", "'2018-06-19 19:07:40'", "'2019-08-20 18:22:38'", null, null, null, "Parks", "Residential new tree request / replacement tree", "2303", "Solved" ]
...etc
}
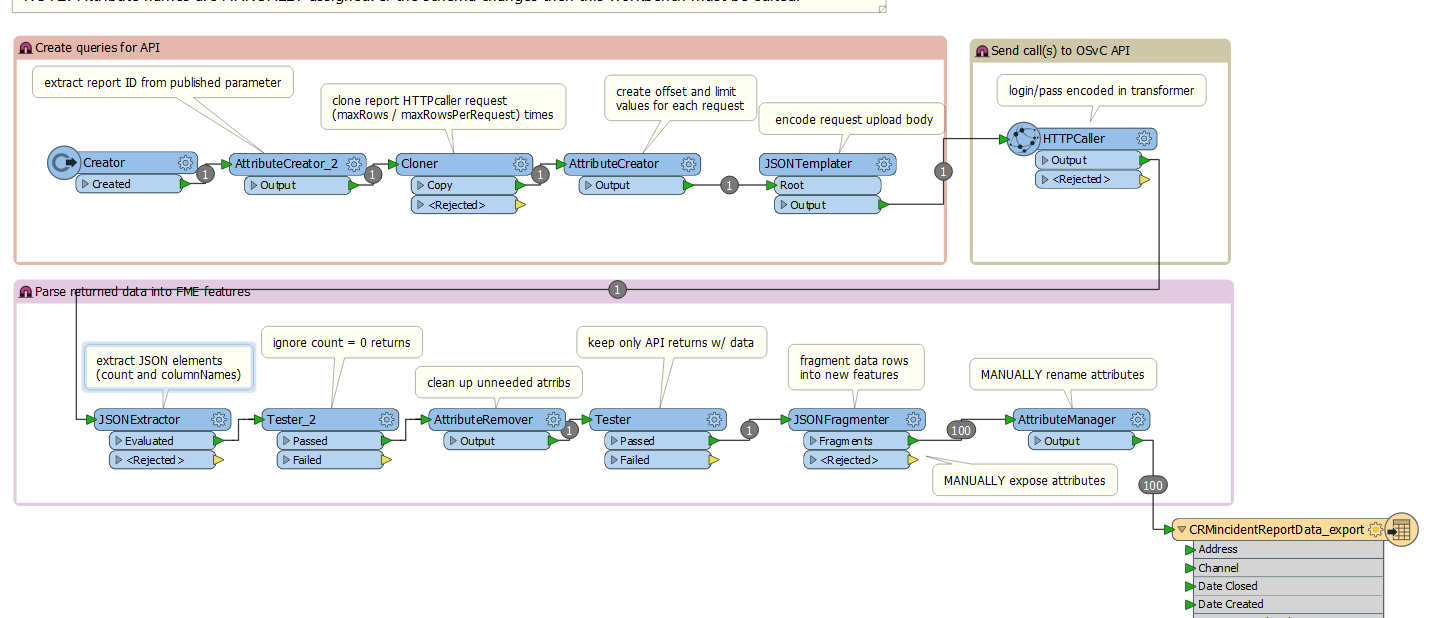
I need to extract the "rows" data into FME features with attributes so that they can be processed and eventually written out to CSV.
How can I accomplish this? I've been able to use a JSONfragmenter with the query json["rows"][*] to separate out the features but I'm having trouble creating the attributes. How do I expose the attributes array{0}, array{1}, array{2}, etc with the correct columnNames?
If possible, I'd like to do it dynamically because there is every possibility that the schema will change down the road and I'd rather not have to edit the workbench. Do I have have to hardcode the columnNames into my workbench?
Suggestions appreciated!



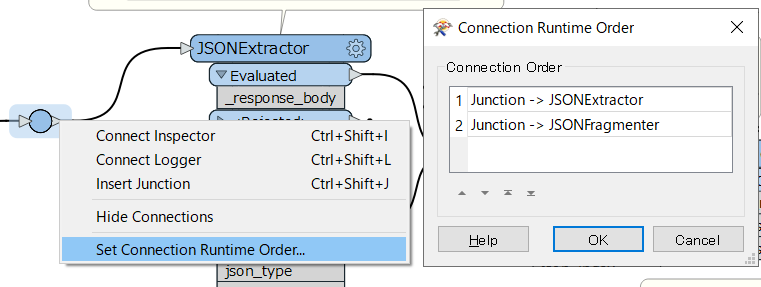
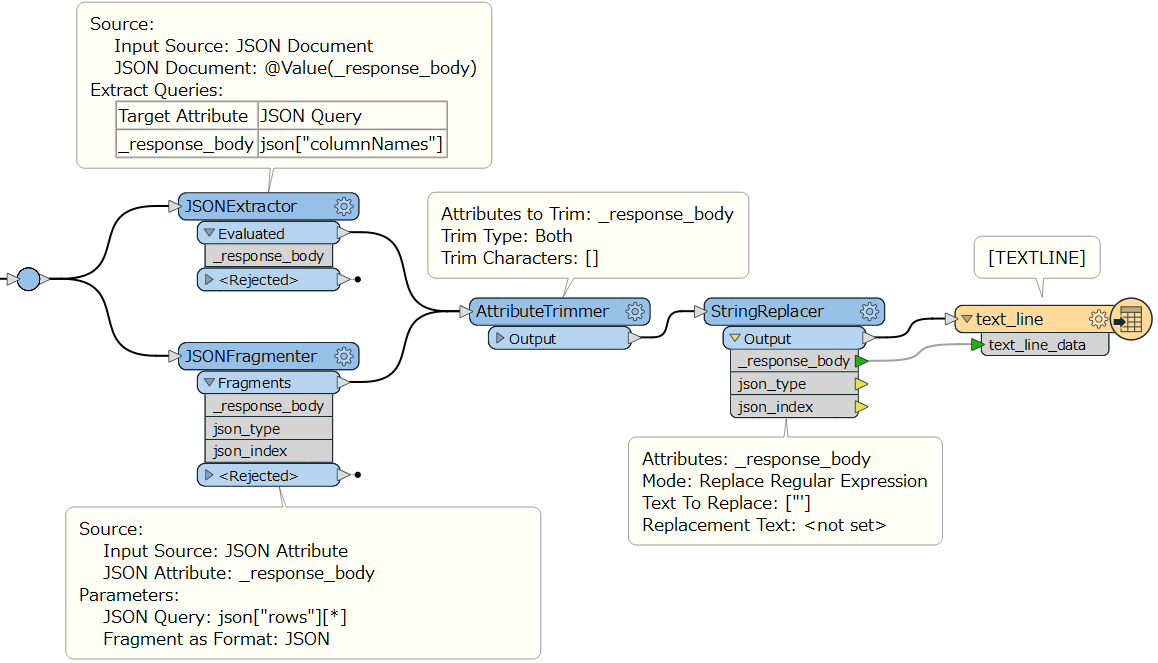 Note: the JSONExtractor should run before the JSONFragmenter. You can control the order by the Junction right-click menu > Set Connection Runtime Order.
Note: the JSONExtractor should run before the JSONFragmenter. You can control the order by the Junction right-click menu > Set Connection Runtime Order.