i could do a list of layers of geodatabasae, but if are some layer empty, i don´t know to do read the name of this layer an export to writer.



Userlevel 4
 +30
+30
- Evangelist
- 1880 replies
-
26 October 2018

Hi @ftl
For to have a better investigate your case, could you share us your Workspace template us?
Thanks,
Danilo


Userlevel 6
 +33
+33
- Celebrity
- 2345 replies
-
26 October 2018

My guess is you need to revise an existing file geodatabase? The way I do this is copy the original to both input and output folders. Read the input geodatabase, write to the output geodatabase, using insert and truncate existing. This way the intelligence in the geodatabase (domains, indices, topology etc) will not get lost.
But the way to read the all the FeatureClasses from a GDB:
- Use a FeatureReader and get the results from the <schema> outputport.
- Use a Classic Reader with the format "Schema (Any Format)".
To write empty FeatureClasses to a GDB:
- Find the empty FeatureClasses by FeatureMerging the Schema Features to the Data Features. SchemaFeatures as Requestor, Unmerged Requestor are Schema Features without Data Features.
- Create dummy records for empty FeatureClasses and send them to a FeatureWriter.
- Delete the dummy records. (Multiple ways but SQL to run after write is one way to do this.)

Userlevel 2
 +17
+17
- Contributor
- 7538 replies
-
26 October 2018

If you just need to read existing layer (feature class) names from a File Geodatabase dataset, the FeatureReader (Features to Read: Schema Features) help you. Each feature output via the <Schema> port has an attribute called "feature_type_name", which stores a feature class name.
 +1
+1
If you just need to read existing layer (feature class) names from a File Geodatabase dataset, the FeatureReader (Features to Read: Schema Features) help you. Each feature output via the <Schema> port has an attribute called "feature_type_name", which stores a feature class name.
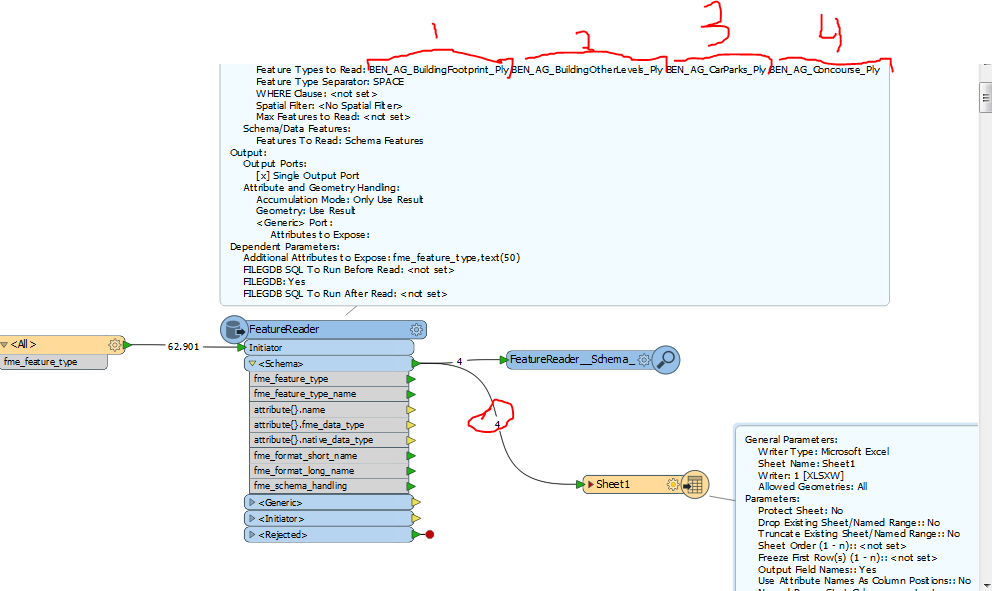
This is a small example of the geodatabase, because it really reads 478 layers
and only this 4.
And only this example of 4 layers with 63000 elements, has taken 106 seconds. If I have 478 layers with millions of elements, how long would it take? I think a lot.
+1
My guess is you need to revise an existing file geodatabase? The way I do this is copy the original to both input and output folders. Read the input geodatabase, write to the output geodatabase, using insert and truncate existing. This way the intelligence in the geodatabase (domains, indices, topology etc) will not get lost.
But the way to read the all the FeatureClasses from a GDB:
- Use a FeatureReader and get the results from the <schema> outputport.
- Use a Classic Reader with the format "Schema (Any Format)".
To write empty FeatureClasses to a GDB:
- Find the empty FeatureClasses by FeatureMerging the Schema Features to the Data Features. SchemaFeatures as Requestor, Unmerged Requestor are Schema Features without Data Features.
- Create dummy records for empty FeatureClasses and send them to a FeatureWriter.
- Delete the dummy records. (Multiple ways but SQL to run after write is one way to do this.)
+1
Hi @ftl
For to have a better investigate your case, could you share us your Workspace template us?
Thanks,
Danilo
I just want to know which is the easiest way to read only the name of the layers of a geodatabase without having to read all the elements, one by one, that are inside.
thank
FTL
Userlevel 2
+17
- Contributor
- 7538 replies
-
27 October 2018
great idea, but if I do what you tell me, I keep reading all the elements inside the layer. and if I have thousands of elements, it reads them all and the process takes a long time to get only the name of the layers.
This is a small example of the geodatabase, because it really reads 478 layers
and only this 4.
And only this example of 4 layers with 63000 elements, has taken 106 seconds. If I have 478 layers with millions of elements, how long would it take? I think a lot.
+1
You don't need to read elements. Just create a single feature with a Creator transformer and send it to the FeatureReader as an initiator.
You are great, that was the idea .....This way the list is removed in a quick way. As I was doing, I only took out the ones that contained elements inside and not the empty ones. Knowing the complete list I can know which has data and which does not.THANK YOU
Reply
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.