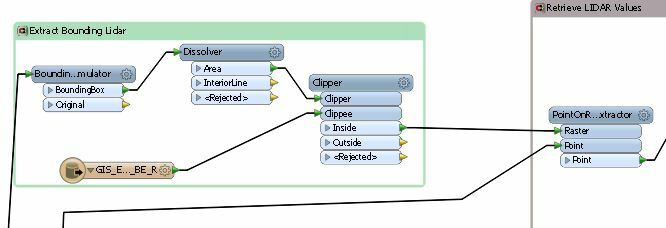
I am having some more performance issues with the workflow displayed below,
basically my inputs are
- ~11 TB 1m Lidar Surface
- ~500,000 - 3,000,000 points
Original, I just had the LIDAR reader directly connected to the PointonRasterExtractor
but that caused memory issues
I have taken these steps so far
- Added a bounding Accumlator
- Dissolver into 1 feature
- Clipper to extract only the areas of LIDAR I need
- Than extracted the points