The Dissolver, set to group by a unique identifier (parcel number for example) should do the trick.
I would try to create tiles in a parent model so that every tile contains 1 or more complete parcels.
In the child model, you can filter those buildings that are located in this particular parcel and just keep working parcel per parcel. Doing so will result in an easier model since you can calculate the statistics directly with the correct data.
However keep in mind that, if there are a lot of parcels, the time necessary to start a new workbench might influence the time to run the model drastically.
The Dissolver, set to group by a unique identifier (parcel number for example) should do the trick.
I tried this before, but it did not work..
I tried this before, but it did not work..
Can you elaborate? What happened exactly?
create a grid the same size as your intended tiler.
Filter out all parcels wich are crosed by this grid.
Use tiler on non-crossed objects.
Process crossed objects separately.
You can also assign the crossed objects to a tiel by for instance testing for inside point in tile.
If u prefer straight tiling, you can recontsruct objects by dissolving only the split objects (to save time) grouped by tilerow,tilecolumn and its unique id.
Full tiling can make it possible to use parallelprocessing btw.
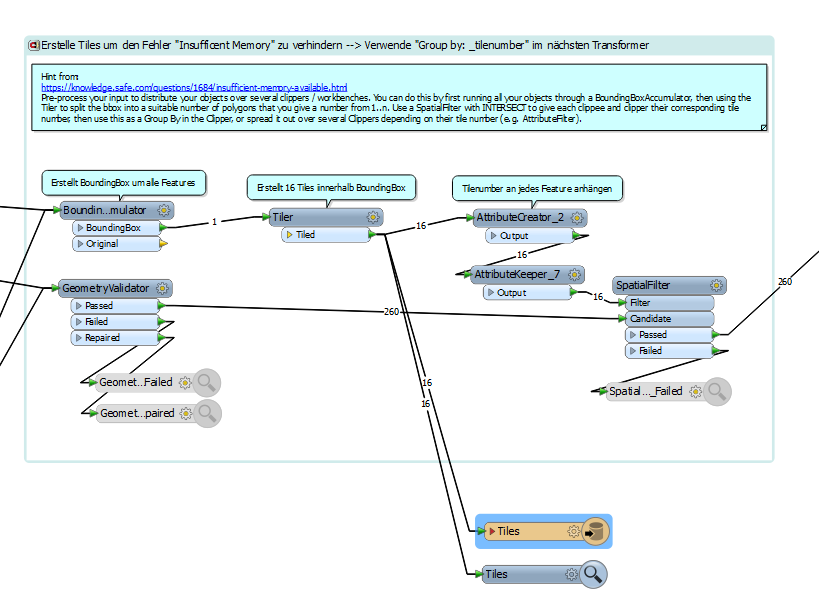
I noticed some German annotation.
Can you use another dividing area (like counties "Kreis") to divide the dataset in a way that parcels do not cross the subdivisions of your dataset?
That would make it a lot easier.
Worth trying as well on 64 bit FME if you have a machine with lots of memory.