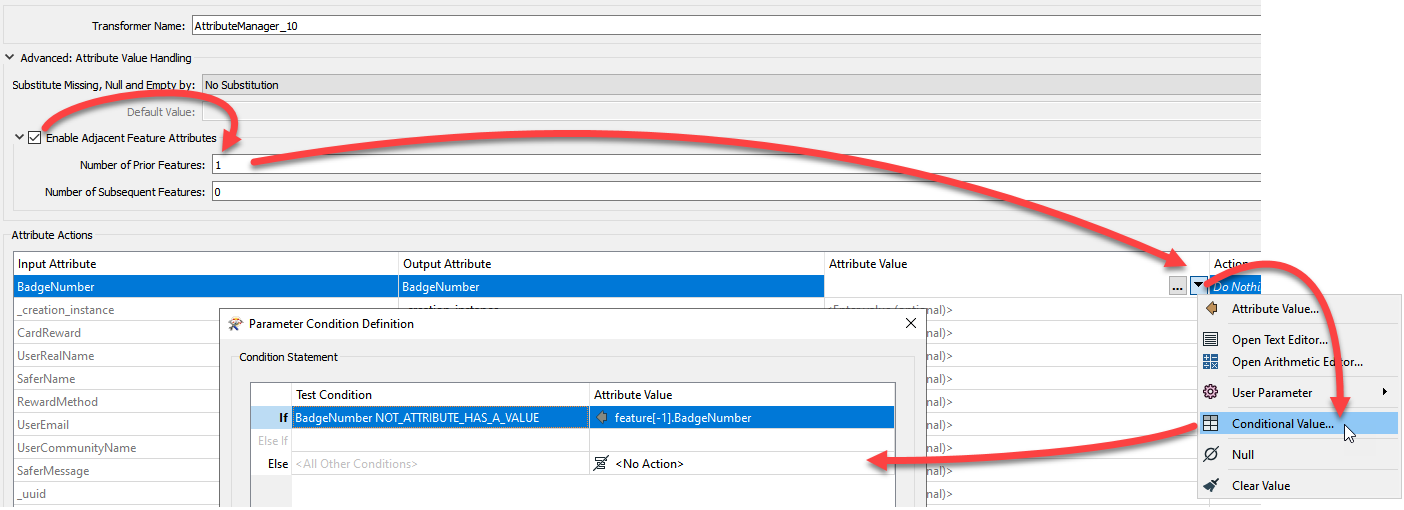
Scenario:
Assuming A = 1, B= 3, C=4, How do I use FME to work out the rest of the blanks

Much Appreciated

Scenario:
Assuming A = 1, B= 3, C=4, How do I use FME to work out the rest of the blanks
Much Appreciated
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.