Hi all,
FME amateur here!
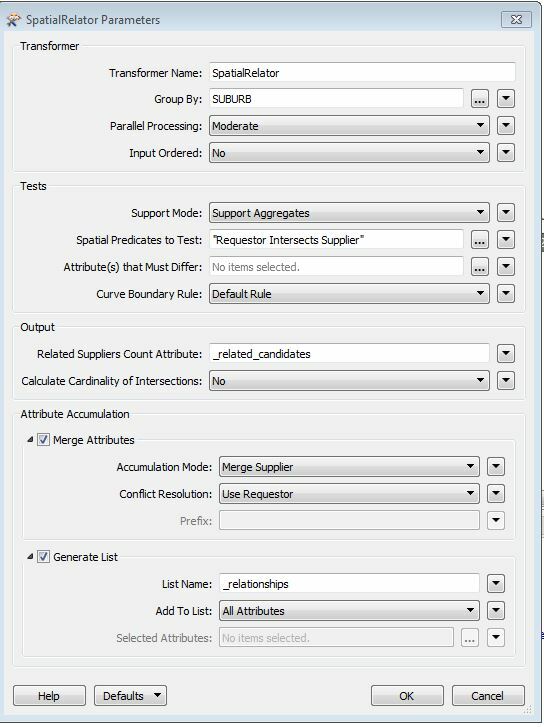
I'm trying to increase the performance of my model. The performance is vastly improved when I use the Group By setting and Parallel Processing in my SpatialRelator.
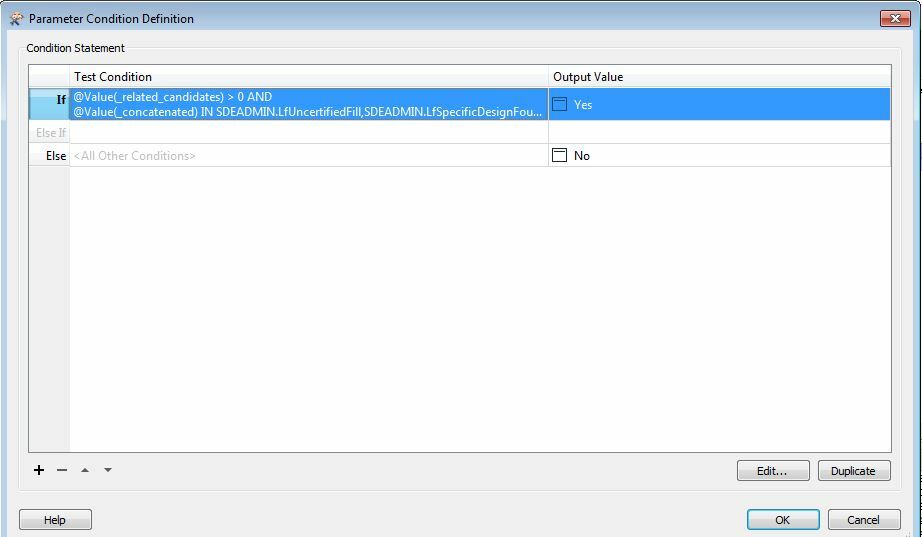
The SpatialRelator is followed by an Attribute Creator which uses a conditional query (combination the number of related_candiates and dataset name) to set a value.
Without the Group By and Parallel Processing FME will correctly tell me the number of related features in the related_candidates field. However when I put the Group By setting on - every value in the related_candidates field is 0.
Does anyone how to fix this?
Ta