I am working with FME 14 on a Win7 machine (8Gb).
I have temopral data of same dataset where the columns are 'Official Name', 'Brand Name', 'FeatureId' etc.
So, what I need to do is-
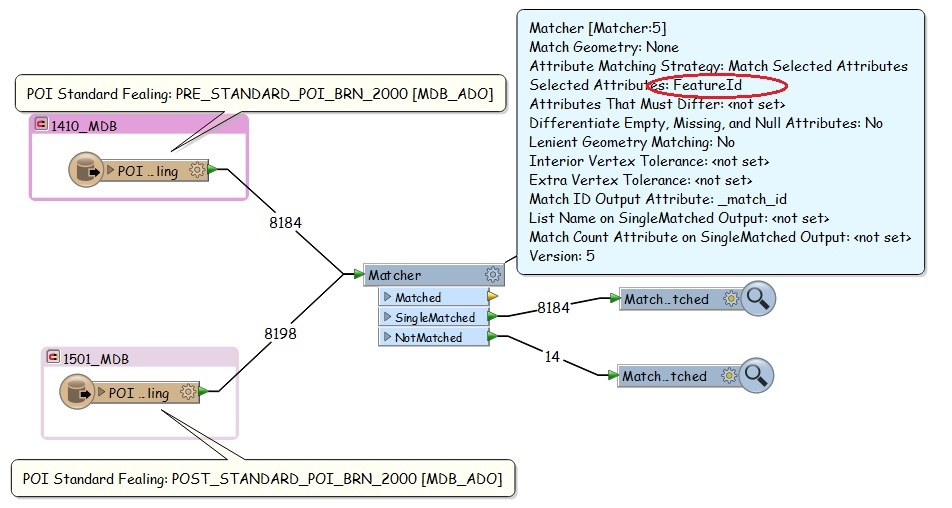
1) Find out how many FeatureId are matching.
2) Only if the FeatureId is matching, then how many Official Names, Brand Names, etc are matching.
I tried doing it with Matcher. I got the FeatureIds correct. Now, if I connect the output of FeatureID to check for Brand Names, the output is wrong. But, when I connect Brand Names with reader, the output is awesome.
Is there a way to get it correct? ):