
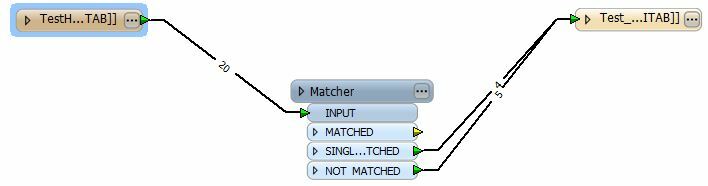
I have the following workspace created to remove duplicates.(Note - I need to remove duplicates based on geometry only as the attribute data is not enough to go on which is why I am using "Matcher)
I tested it out with some sample duplicate object data I created (point, line, polygon objects) are what we deal with here. This gives me any object from the source that is geometrically unique, and for lack of terms "flattens" all duplicates based on geometry.
The problem I have is that in my source data I a schema with 25 columns and I want to maintain all of this column data "exactly" as it is in the source.
Is this possible to carry this data over "as is" into the final exported file that no long has duplicates? With my beginner level status, I am guessing I would have to possible add a data inspector somewhere?
Thanks for any help in advance.
Nick