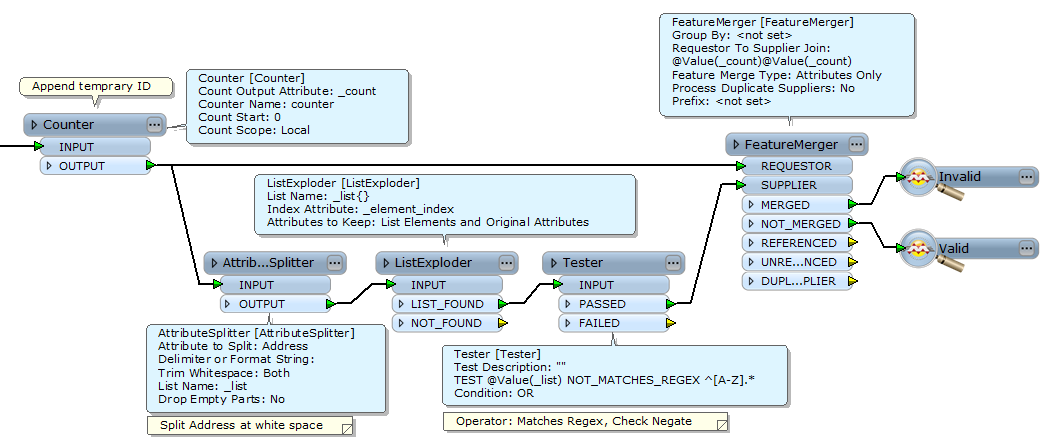
St. Petters Road is the valid space(it need not be flagged); but
St. Pe tters Road is invalid,
and I need to flag the invalid attributes in a new column as 0 and 1
Can we do that with transformers ?


 +2
+2St. Petters Road is the valid space(it need not be flagged); but
St. Pe tters Road is invalid,
and I need to flag the invalid attributes in a new column as 0 and 1
Can we do that with transformers ?