



I have a very basic dynamic workbench that is reading data from SQL Server. Before writing data to a postgis database it is changing an attriubte name with SubstringExtractor.
But it is extremely slow doing so after almost 3 hours 150 000 objects has been read by the reader. Typically 100 000’s of objects is handled in matters of minutes.
It is reading about 25 different feature classes I need to migrate daily.I cant wait hours for the workbench to be complete.
2024-09-27 15:11:02|6056.7| 0.8|INFORM|Reading source feature # 47000
2024-09-27 15:11:53|6106.9| 50.2|INFORM|Reading source feature # 47500
It takes 50 seconds to read 500 features?
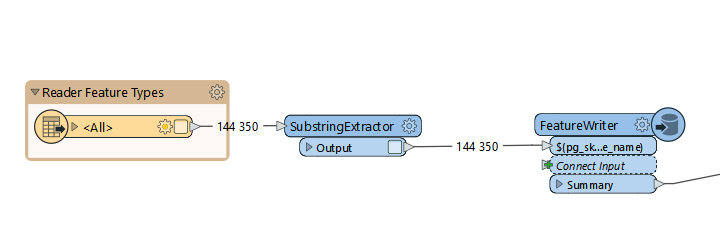
What is wrong? Why is the process so slow? I cannot understand where the bottle neck is.




")


