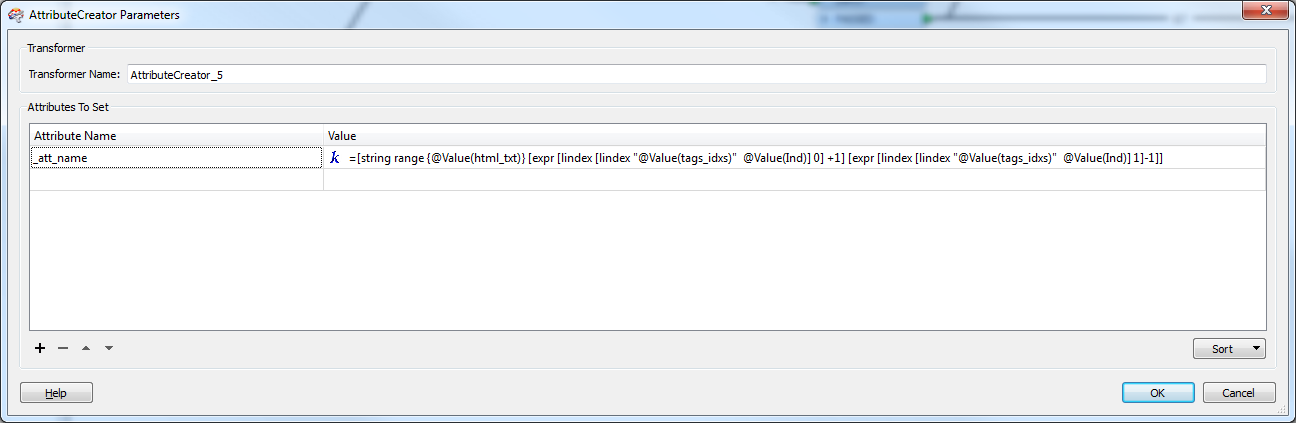
But i thought, giving it more exposere..
") (though this might be bad for my ranking in the community ehehehe )
(though this might be bad for my ranking in the community ehehehe )
original input:
Sample clob:
<body>
<h3>32594. * (T) Oslofjorden. Oslo. Sjursøya. Lysbøyer. Nye posisjoner<em> ( Light buoys. New positions).</em></h3>
<p><strong><strong>Slett</strong></strong> tidligere Efs (T) 09/441/09<br /><em>(<strong><strong>Delete</strong></strong> former Efs (T) 09/441/09)<br /></em>På grunn av utfylling i sjø på nordsiden er følgende sjømerker flyttet:<br /><em>(Due to reclamation north of Sjursøya Mole the following light buoys has been moved):<br /></em>a) Grønn lysbøye fra posisjon (1) til (2):<br /><em>(Green light buoy from position (1) to (2)): <br /></em>WGS84 DATUM<br />(1) 59° 53.223' N, 10° 44.607' E <br />(2) 59° 53.242' N, 10° 44.611' E <br />ED50 DATUM<br />(1) 59° 53.250' N, 10° 44.693' E <br />(2) 59° 53.269' N, 10° 44.697' E <br />NGO DATUM<br />(1) 59° 53.176' N, 10° 44.896' E <br />(2) 59° 53.195' N, 10° 44.900' E <br /><span style="background-color:Yellow;">b) Midlertidig utlagt gul lysbøye fra posisjon (1) til (2):<br /><em>(Temporary yellow light buoy from position (1) to (2)): <br /></em>WGS84 DATUM<br />(1) 59° 53.222' N, 10° 44.637' E <br />(2) 59° 53.246' N, 10° 44.659' E <br />ED50 DATUM<br />(1) 59° 53.249' N, 10° 44.723' E <br />(2) 59° 53.273' N, 10° 44.745' E <br />NGO DATUM<br />(1) 59° 53.175' N, 10° 44.926' E <br />(2) 59° 53.199' N, 10° 44.948' E <br />c) Midlertidig utlagt gul lysbøye fra posisjon (1) til (2):<br /><em>(Temporary yellow light buoy from position (1) to (2)): </em><br />WGS84 DATUM<br />(1) 59° 53.252' N, 10° 44.761' E <br />(2) 59° 53.252' N, 10° 44.777' E <br />ED50 DATUM<br />(1) 59° 53.279' N, 10° 44.847' E <br />(2) 59° 53.279' N, 10° 44.863' E<br />NGO DATUM<br />(1) 59° 53.205' N, 10° 45.050' E <br />(2) 59° 53.205' N, 10° 45.066' E<br /></span>Kart <em>(Charts)</em>: 4, 401, 452. (KildeID 0). (Oslo Havn KF, 1. desember 2010).<br /><br /></p>
</body>
Extract values form html fragment..
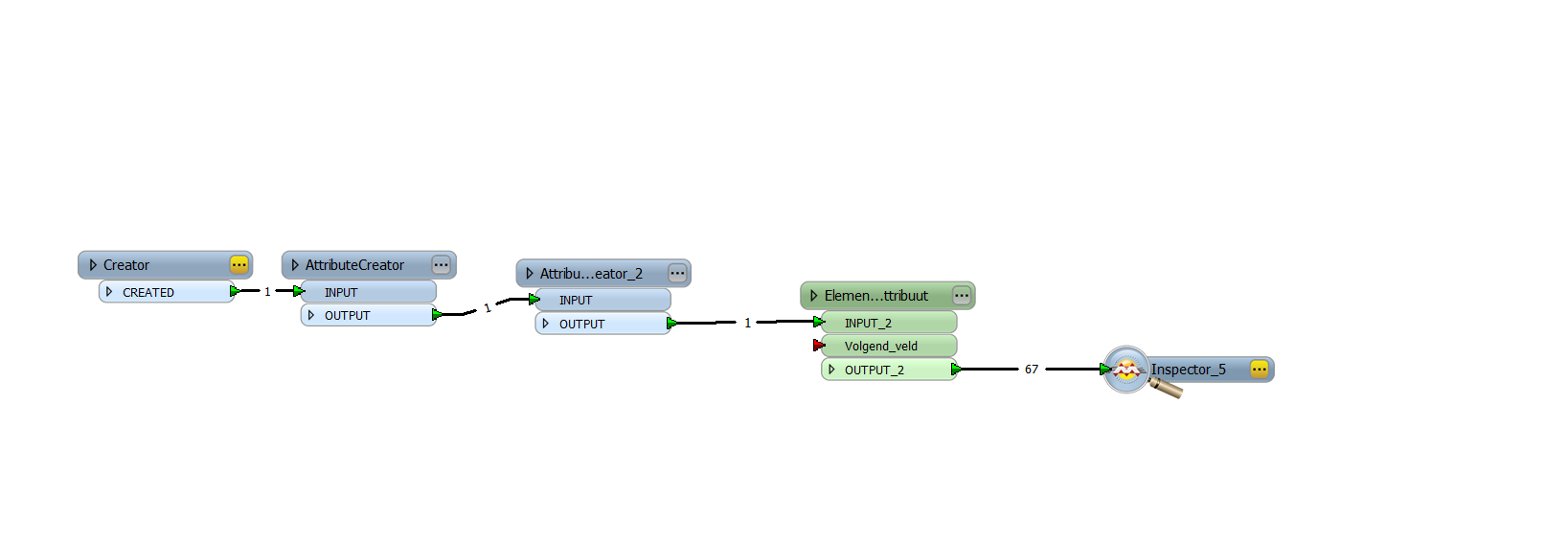
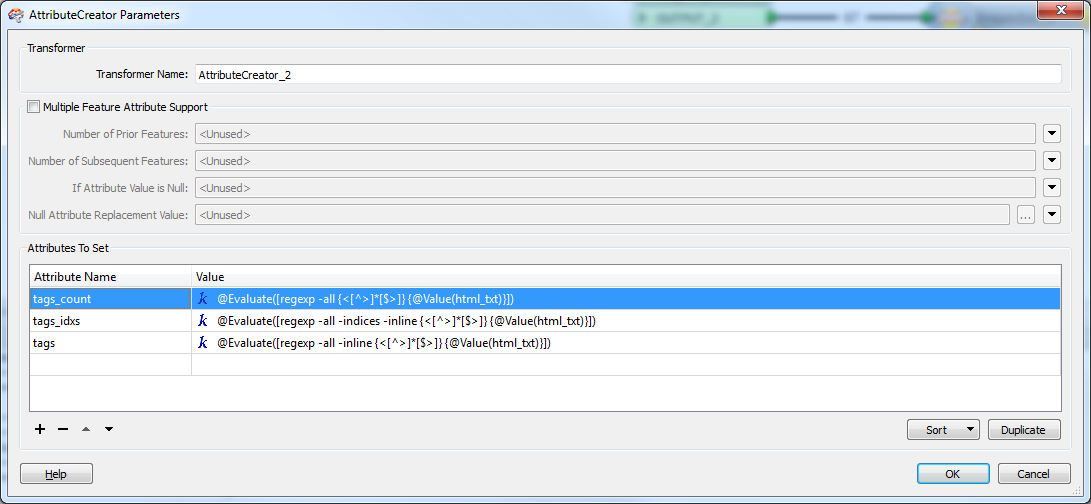
this is for AttributeCreator2.
(Creator 1 just reads in the html textfragement posted in aforementioned issue.)
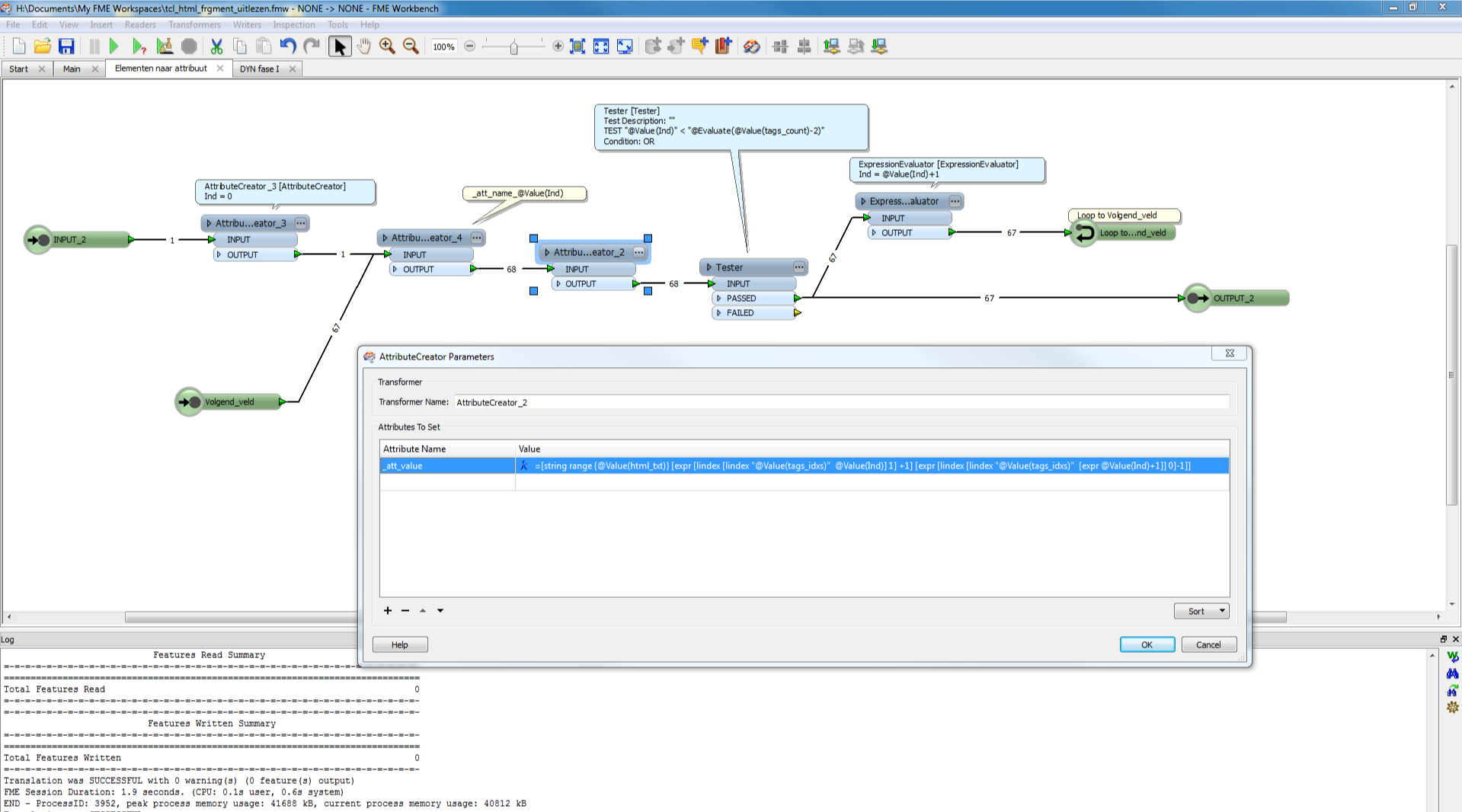
reads better this way....
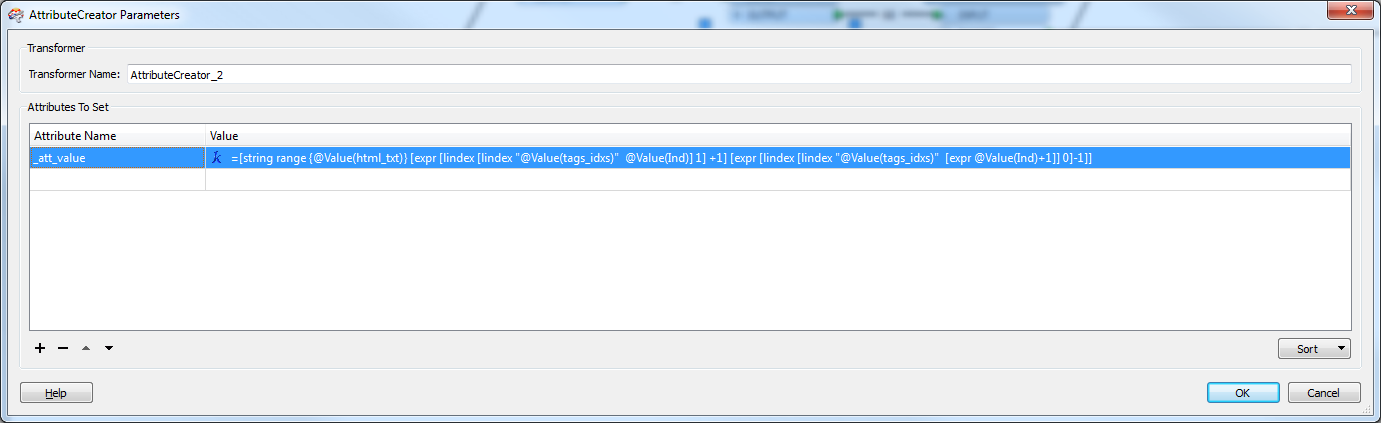
and result:
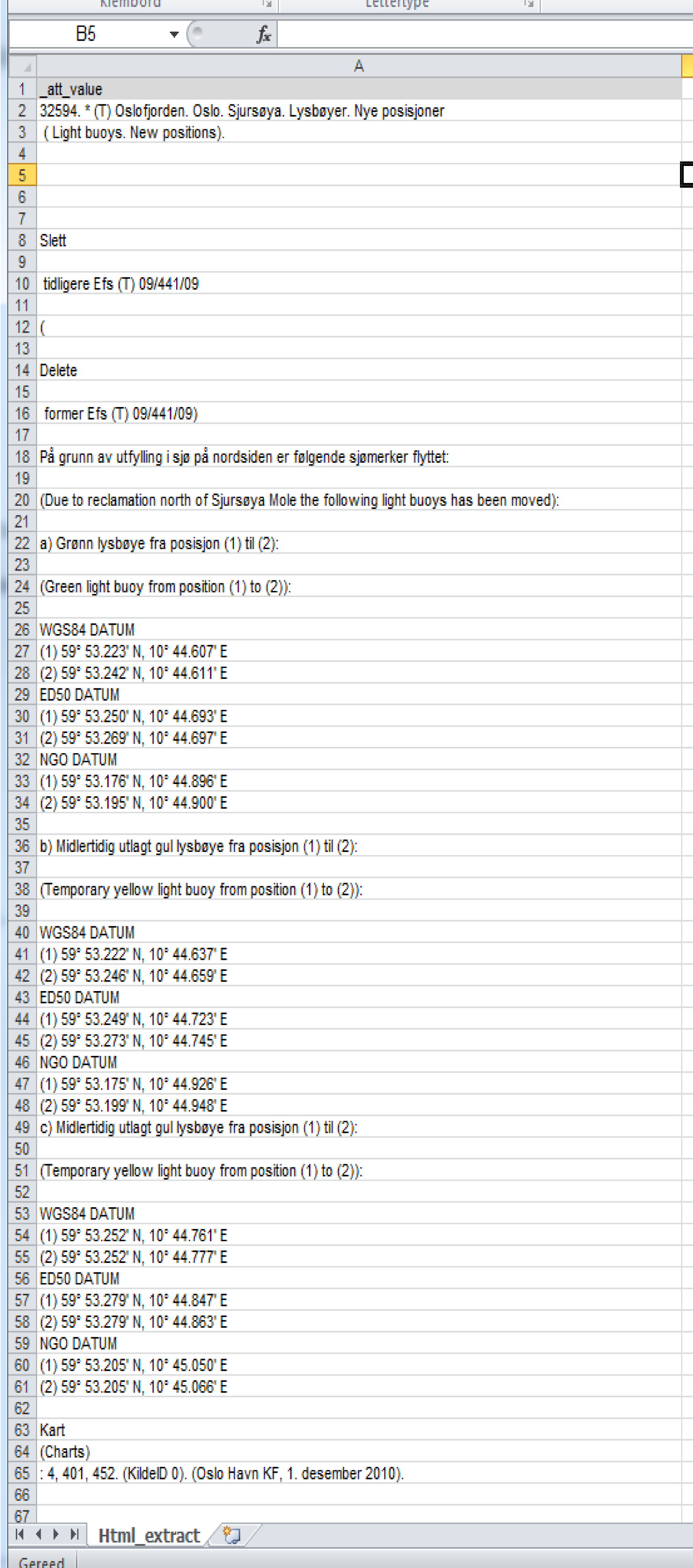
...tcl..simple, elegant and Skickin!
have fun