My first “proper” Custom Transformer for maybe public consumption is AttributeTruncationChecker (attached)
I’m not sure I have totally debugged it, but it seems to work now in most samples I throw at it. Will leave it here for the Community to possibly use it and improve it.
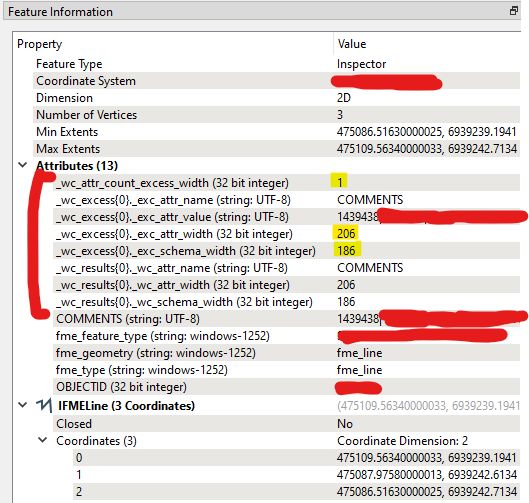
This is trying to address possibly one of the more common headaches we run into, in getting the dreaded Truncated Values warnings in the Translation Logs when a Feature Attribute string is too long for the Writer destination field. At the moment, it is very time-consuming to track these down in large Feature datasets/Multiple Feature Datasets being written simultaneously, to design and run some Transformations to try to find the offending Features and which Attributes.
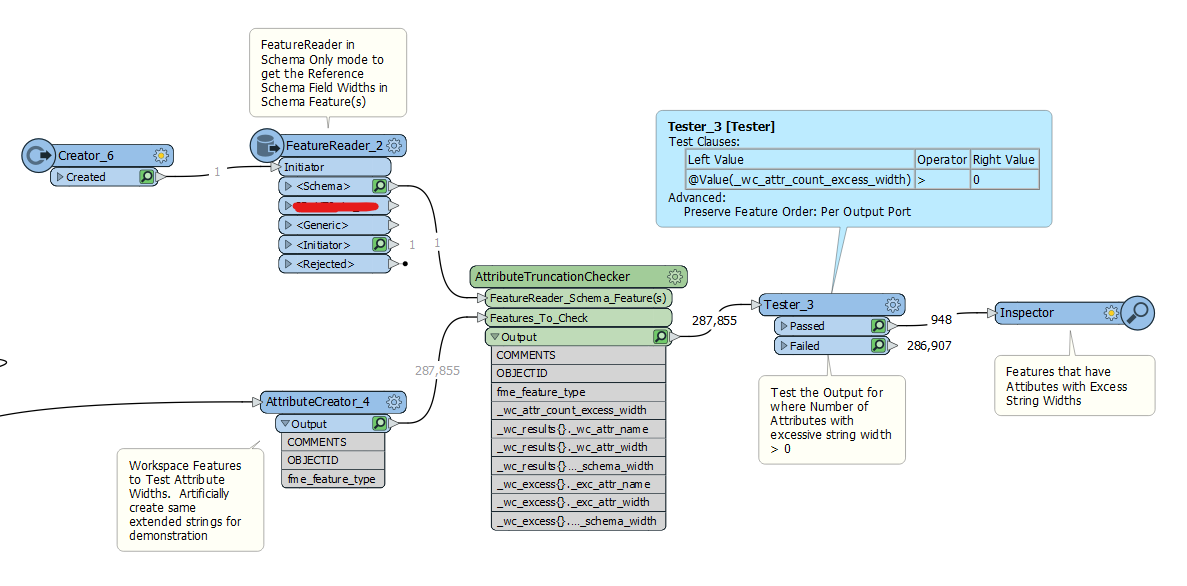
This Transformer aims to detect these in the Workspace, by comparing the Workspace Features to Reference Schema Feature(s), typically from a FeatureReader. Originally I found I could “solve” this relatively easily with AttributeExploder based standard Transformers and a bit of optimisation using RegEx and BulkAttributeRemover to not have to explode non-text Attributes, but the performance just did not scale to large feature datasets and so I had to turn to Python Feature iteration.
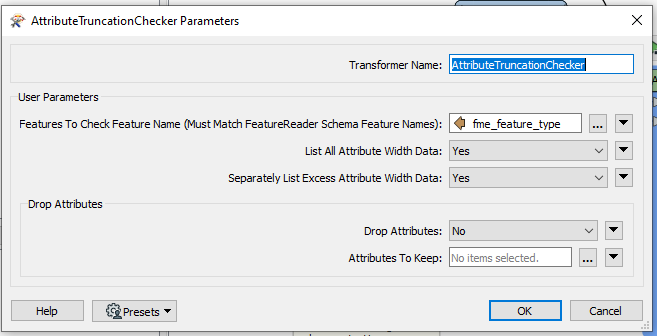
Output (Most Detailed Reporting Mode)