


Hi,
Yesterday I came across the situation where I wanted to split a text file into several portions. For 'new lines', the file contained both single Line Feeds (i.e. LF or \\n) as Carriage Return - Line Feed (i.e. CRLF or \\r\\n) combinations. Thus both the Unix End Of Line (EOL) methodology and the Windows EOL methodology were present.
I used the StringSearcher to match relevant parts of the text file, and then wanted to use (concurrent) all_matches{}.startIndex to fetch the relevant portions of the file.
However, I found out that when I then use the found startIndex in e.g. the SubstringExtractor, it doesn't doesn't return the same (starting) characters as found in the match. Digging a bit deeper, it seems that the StringSearcher all_matches{}.startIndex seems to skip counting CR (\\r). I'm guessing it identifies CRLF (\\r\\n) as an individual character c.q. index?
See the screenshot below for a demo workspace illustrating this issue. Also, I found that the equivalent @FindRegularExpression() does seem to find the correct startIndex.
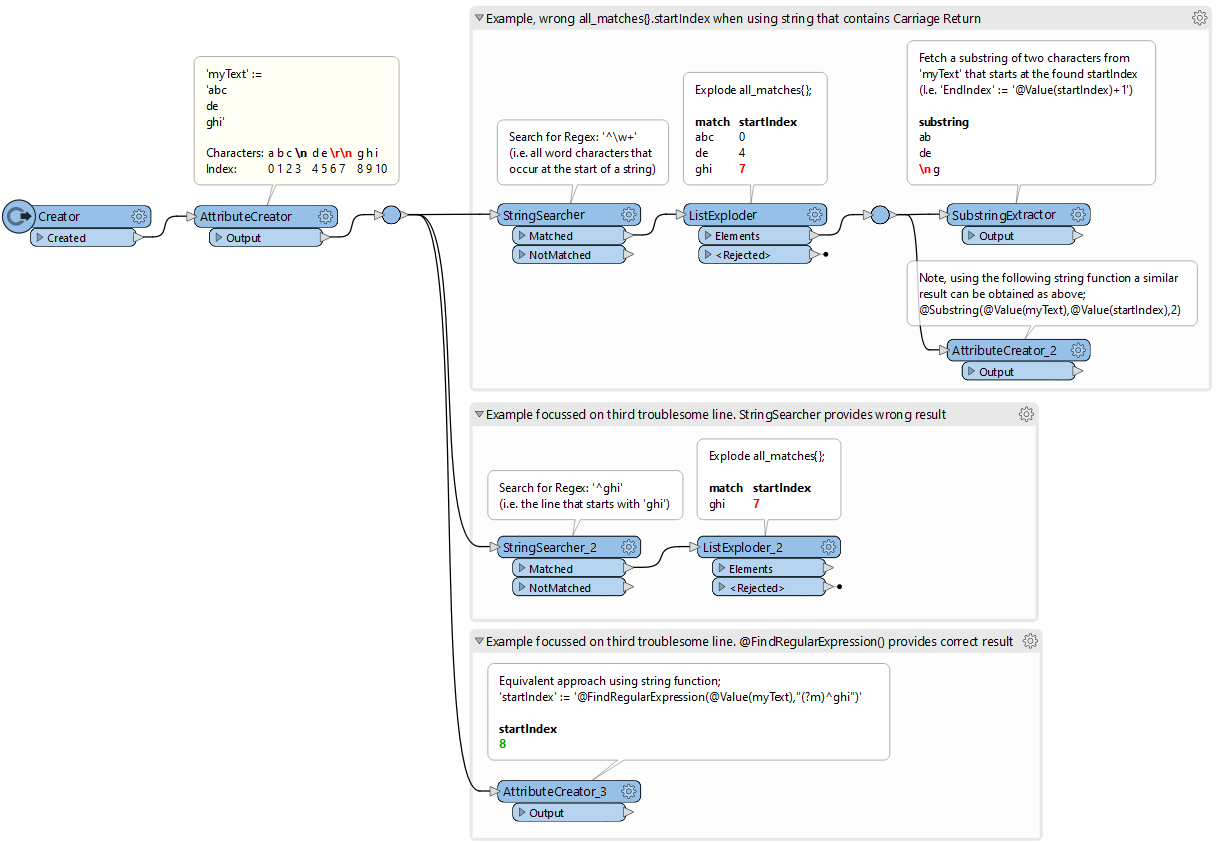 Curious to hear other people's thought on this, I'm guessing this is a bug of the StringSearcher.
Curious to hear other people's thought on this, I'm guessing this is a bug of the StringSearcher.
Kind regards,
Thijs
ps. While working on this issue, I also came across a couple of additional observations. Maybe these can also be looked at/investigated.
- The StringSearcher uses multi-line-mode by default, wheras @FindRegularExpression() uses non multi-line-mode by default. I.e. I needed to add the Regex Mode modifier '(?m)' to make the @FindRegularExpression() string function behave as desired.
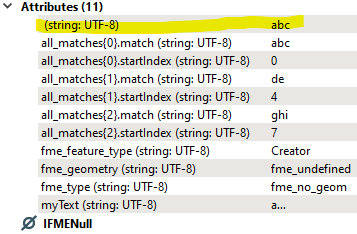
- When optional 'Matched Result' parameter of the StringSearcher Transformer is left blank, an invisible attribute is created (with <space> for its name and the firstMatch for its value).
- E.g. for the StringSearcher;
- Examples of 'correctly implemented' optional attributes;
- Creator - Creation Instance (FME default '_creation_instance')
- ListExploder - Element Index (FME default '_element_index')
- Examples of 'incorrectly implemented' optional attributes;
- StringSearcher - Matched Result (FME default '_first_match')
- XMLXQueryExtractor - Result Attribute (FME default '_result')
- Implementation of SubstringExtractor and @Substring() function is slightly different. I.e. Both use startIndex, but SubstringExtractor uses 'End Index' for input, whereas @Substring() uses numChars as input. I personally prefer the latter.
- FME documentation on String functions doesn't mention 'SubstringExtractor' as equivalent transformer for @Substring() transformer