")
Bonjour,
J’ai une table avec plusieurs colonnes (23) chaque colonne à la valeur 0, 1, 2 ou 3 dedans. J’aimerais savoir une façon de calculer le nombre de fois dans une ligne que l’on peut retrouver la valeur 1, 2 ou 3 et mettre ce résultat dans 3 colonnes distinctes (une pour le 1, le 2 et le 3) voici l’exemple du résultat :
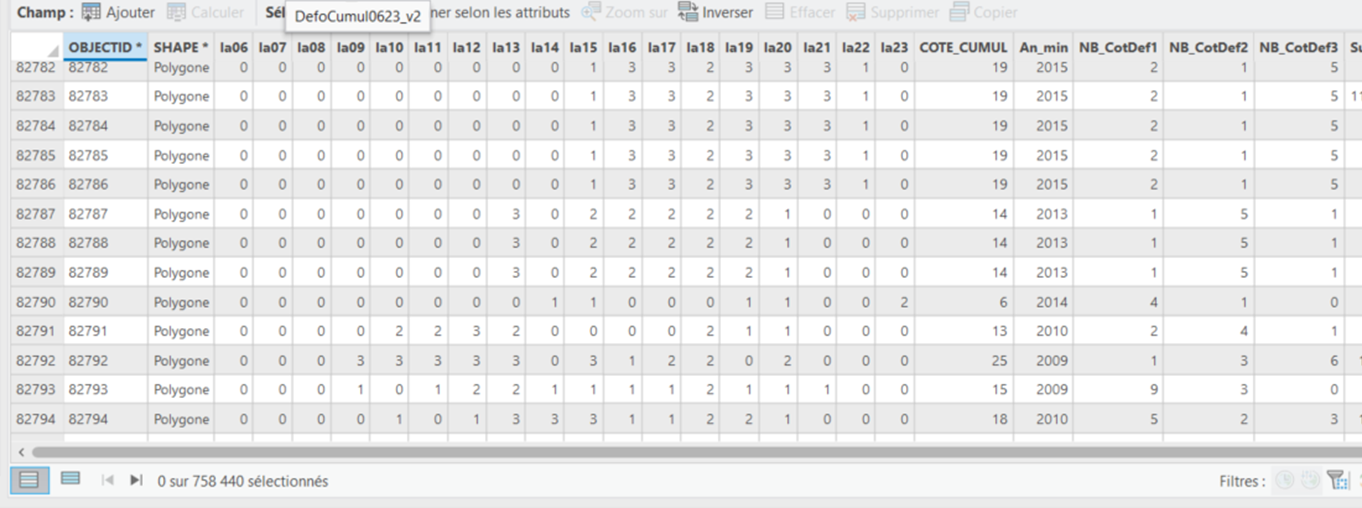
Merci pour votre aide!