


Hi
I need some help with parsing the json response from the rest server api /transformations/jobs/completed with parameter competedState: failed
What I want is a complete table with all attributes except TMI and NMI Directives. From PublishedParameters I only need subsorter and its corresponding value. This is a problem I cant solve. As it is now I can get subsorter and its value but no other attributes like "timeStarted".
It would be great if it was possible to parse the whole json file and get a nice table with only 1 fragmenter.
I attached a workspace where the json code is embedded as an attribute.
Thanks in advance if someone could point me in the right direction.

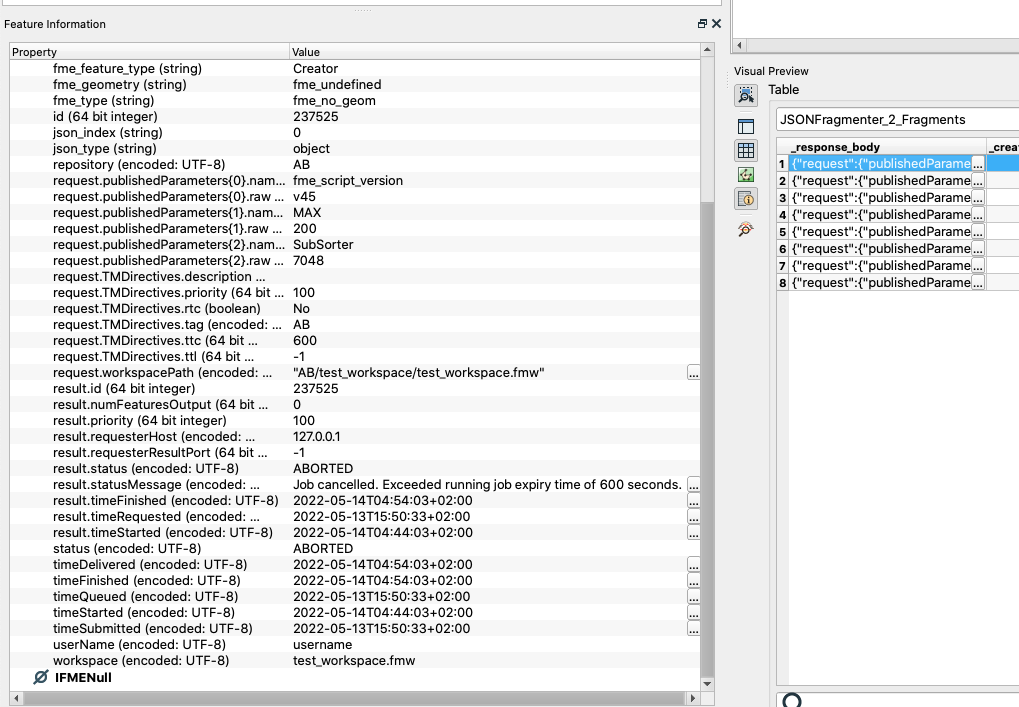 e.g. to expose the status Message you'll need to specify result.statusMessage, or the workspace path would be request.workspacePath.
e.g. to expose the status Message you'll need to specify result.statusMessage, or the workspace path would be request.workspacePath.