
Suppose I have a data containing 10 million records but I want to read every 1 million features and run my processing parallel in 10 batches. Can someone please suggest any method?


What is the sourse dataset format?
shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel

Userlevel 2
 +17
+17
- Contributor
- 7538 replies
-
31 January 2022
shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel
A possible way is to convert the transformers which you need to perform in parallel to a custom transformer, configure its parallel processing parameters, and run it for each group (i.e. block of 1 million features).
The attached screenshots illustrate how you can create a transformer parameter linked to the Group By parameter, and set a parallel mode (minimal or above) to the Parallel Processing parameter.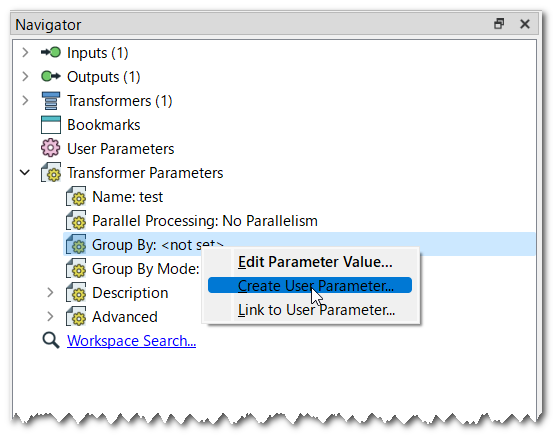
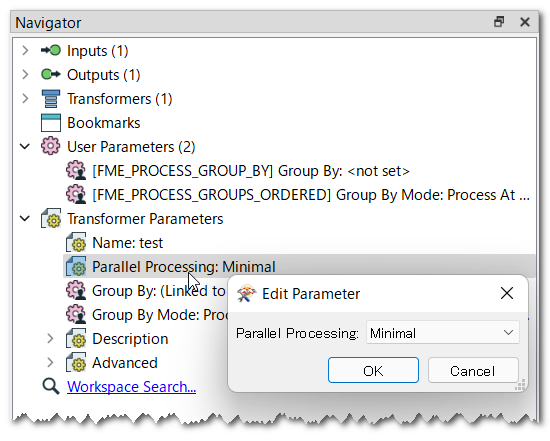
shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel
how we can process it in blocks? like 1 million features then next million features & then the next ? Is there a way to segregate in blocks and run in parallel, I saw all of the features which are going inside the custom transformer through different streams are going together one by one but not in parallel


Userlevel 5
 +29
+29
- Celebrity
- 1109 replies
-
31 January 2022

shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel
Setting the Group By Mode to "Process At End" and using a transformers like the modulo counter to group features into X number of groups
Userlevel 2
+17
- Contributor
- 7538 replies
-
1 February 2022
shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel
I think it would be efficient to keep the order of features, in this case. A possible way is to use a Counter to add sequential number to the features, then calculate group ID (integer number) with this expression.
@floor(@Value(_count) / 1000000)
You can then set "Process When Group Changes (Advanced)" to the Group By Mode parameter.
[Add] The attached screenshot illustrates my intention.
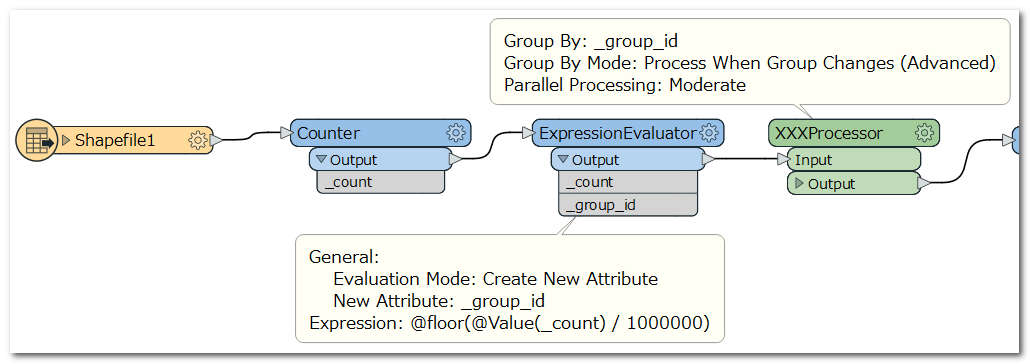
shapefile, but regardless what the format is, I want to send 1 million records or you can say rows (if its in database format) in 1 set and parallel I want to run 10 more batches like this from same series of processes and transformers, just wanted to know how it can be done in batches in parallel
Thank you for the suggestions, appreciate it 😊
Reply
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.