
Dear everyone, I have a workbench which we is using for data download purpose. This workbench is connected with an enterprise gdb (sql server) and reading feature classes and tables and we are downloading data in different format in need basis. So far, through "Published Parameter" we have been successfully downloaded data in csv2, XLSXW, GEODATABASE_FILE formats without doing any programming but when I added "TEXTLINE" writer format in Published Parameter then the download result is producing an empty text file.
Please someone help me out from this problem.
Thanking you
With kinds Regards
Muqit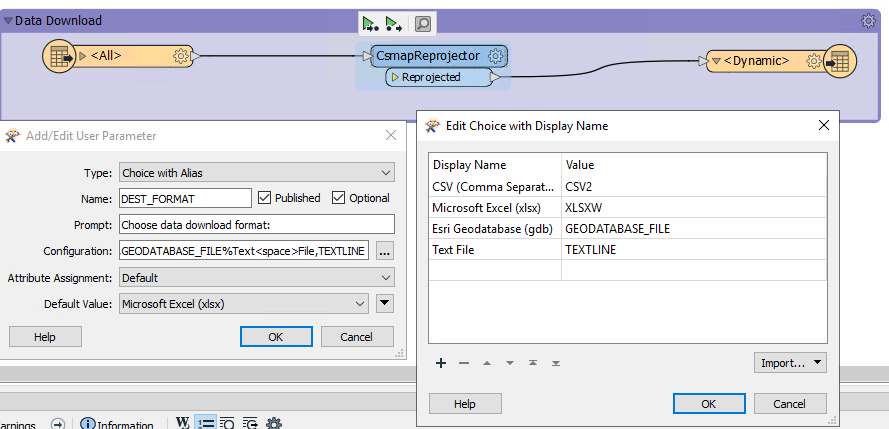


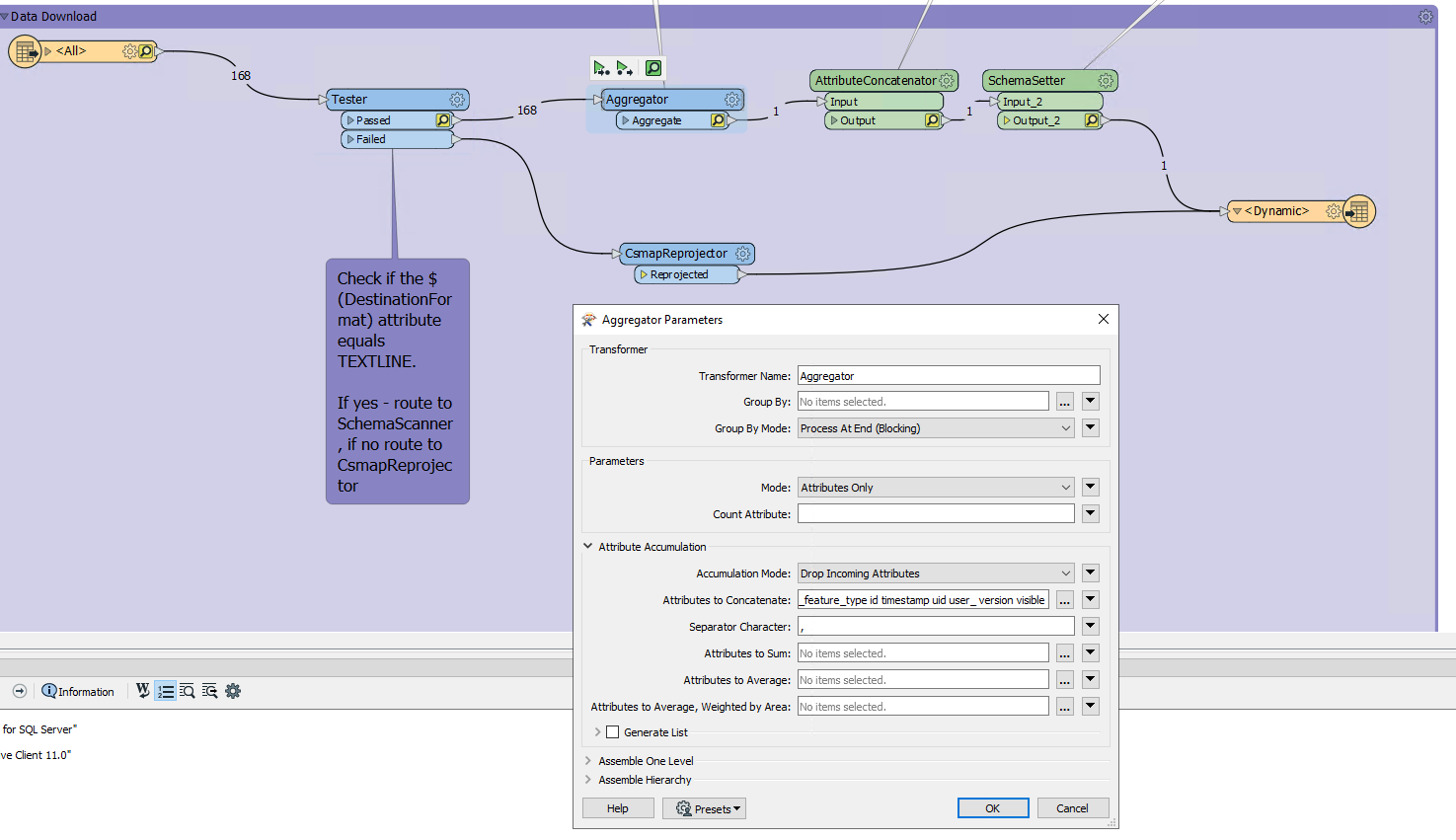
 And I getting data as output like:
And I getting data as output like: 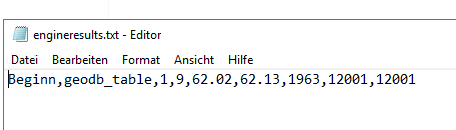 but I also want the column names and after second line values will come seperated by (,) and need to get all values in row wise like a csv file. but the file extension will be .txt .
but I also want the column names and after second line values will come seperated by (,) and need to get all values in row wise like a csv file. but the file extension will be .txt .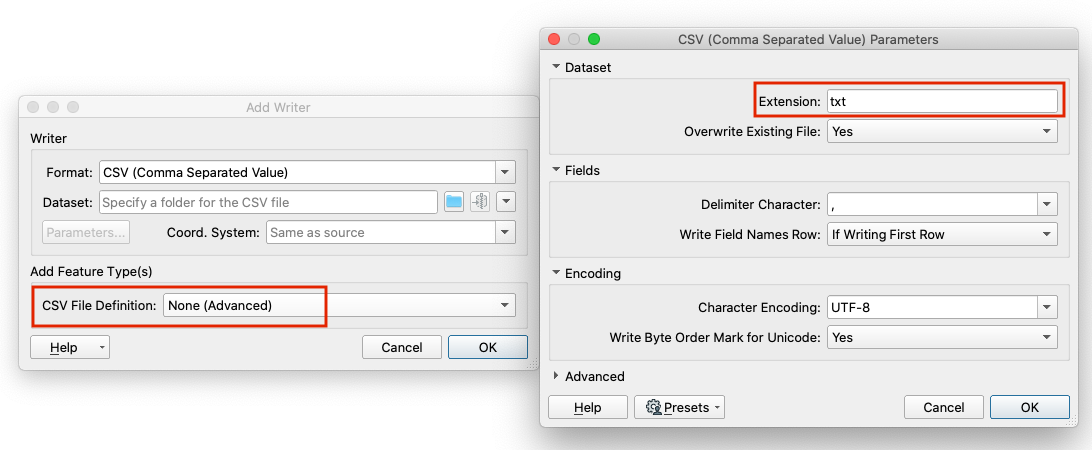 Now, whenever the Generic Writer is set to the CSV2 format, it will use these settings.
Now, whenever the Generic Writer is set to the CSV2 format, it will use these settings. 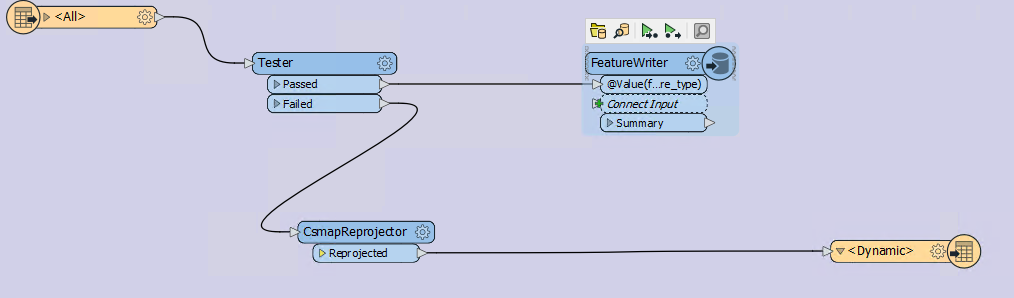 By using tester I just bypass the texfile to a FeatureWritter (which is a csv writer) and in parameters I have used txt as extension.
By using tester I just bypass the texfile to a FeatureWritter (which is a csv writer) and in parameters I have used txt as extension.