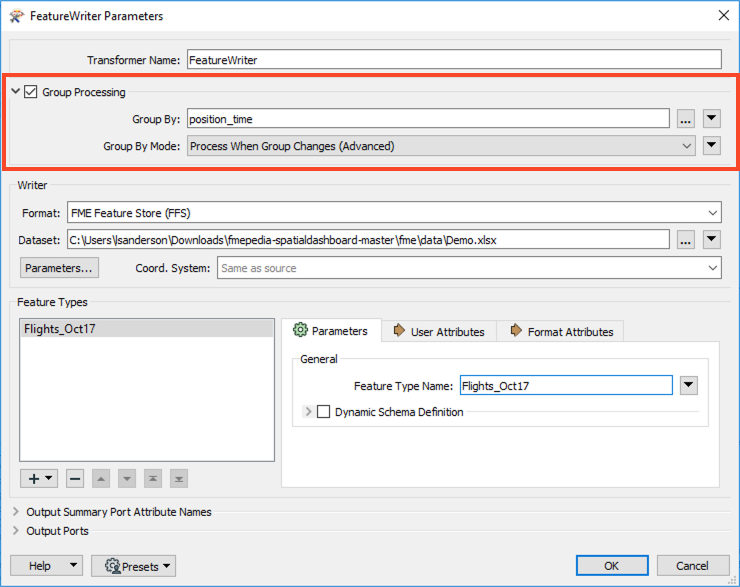
New for FME 2021.0 is Group-By functionality on the FeatureWriter transformer. Group based transformers process data simultaneously based on data groupings. When Group-By Processing is enabled, the user can choose which attribute to use, which divides the data into groups. Additionally, if your data is pre-sorted into groups before entering the transformer, selecting “Process When Groups Change” can speed up the transformation as the transformer isn’t waiting for all of the data before sending the group of data out. In addition, when the groups change in this mode, the current writer will be closed and all its data will be written out before the next feature arrives.
By adding this functionality to the FeatureWriter, data can be forced to be written out chunks at a time by using attribute values to define groups, instead of waiting for the entire transformation to end. This will avoid running out of resources such as file handles or memory in certain scenarios. One example is streaming data, where groups of timestamped and time windowed data arrive at the FeatureWriter, and can then be written out when the next timestamp arrives.
When selecting an attribute to use for Group-By in the FeatureWriter, a warning dialog will appear. This dialog warns the user that when groups are written to the same dataset, it is possible that the output data might be overwritten. This is typically avoided by splitting up your datasets or output feature types using fanout. For more information on fanout, see this article. Additionally, for more information on using multiple inputs with a transformer with Group-By see the question, How does 'group by' option work for transformers that contain multiple input ports