Hi,
I am using FME 2017.0 x64 and the input data is PostGIS data from server
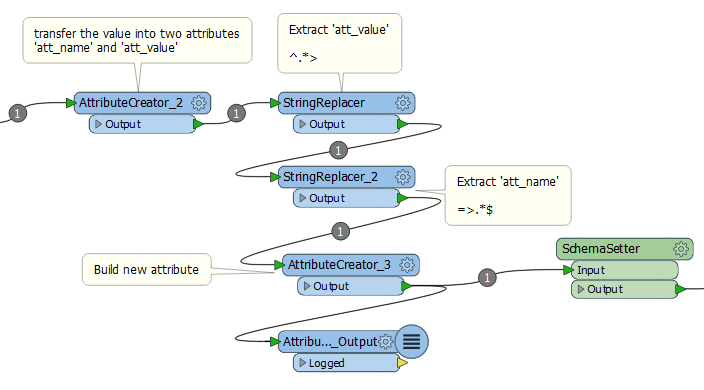
So, there is a column in the table 'other_tags that contains strings as displayed. I want the values in the left of => to be the attribute name and the value in the right of => to be the value of that attribute. The two columns are separated by comma(,).
The catch is the attribute name are not in a certain order, so I found a bit of difficulty to create list.
Moreover, the values in the columns can be multiple, like surface could be- paved, unpaved, asphalt, grass and many more and since the workbench has to be used for multiple countries the string also cannot be defined.
Could there be some easy possible way to extract the values that can make workbench shorter and easier.
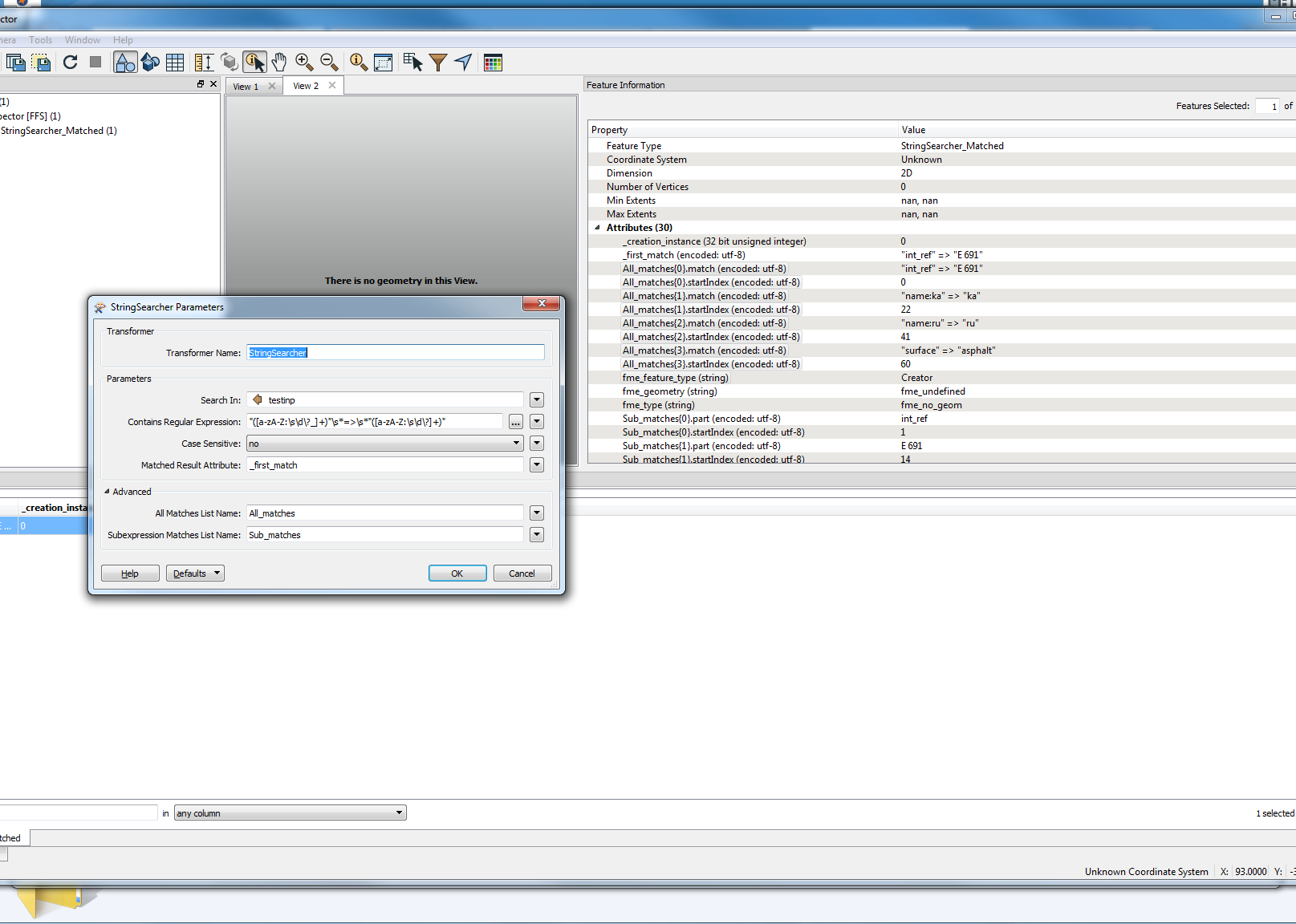
I tried string searcher with regex- surface"=>".*"$ but something is going wrong.
Thanks.