

Hello,
I have one feature reader that reads one table City, then I have another reader that reads table Person and then for each feature from City and for each feature from Person that are merged I'm performing job submitter operation with parameters CityId, PersonId
I would like to change it a bit:
What I would like to achieve is to take all objects from City and then take all objects from Person but then group results from Person to merge every n records into one.
As example:
Lets say I have 2 records in City table:
New York
Chicago
And I have 4 records in Person table:
Person1Person2Person3Person4
In o regular flow I would have JobSubmitter executed 8 times for:
CITY IDPERSON IDCITY IDPERSON IDNew York
Person1
Chicago
Person1
New YorkPerson2
ChicagoPerson2
New York
Person3
Chicago
Person3
New York
Person4
Chicago
Person4
What I would like to do is to group every n row from Person table and merge PersonIds into one attribute and modifie it a bit (by adding '' and ,) so for example for n = 2 job submitter would be executed only 4 times and it would look like:
CITY IDPERSONIDNew York'Person1','Person2'New York'Person3','Person4'Chicago'Person1','Person2'Chicago'Person3','Person4'
For n = 3 it will be also executed 2 times but for n = 4 only 2 times.
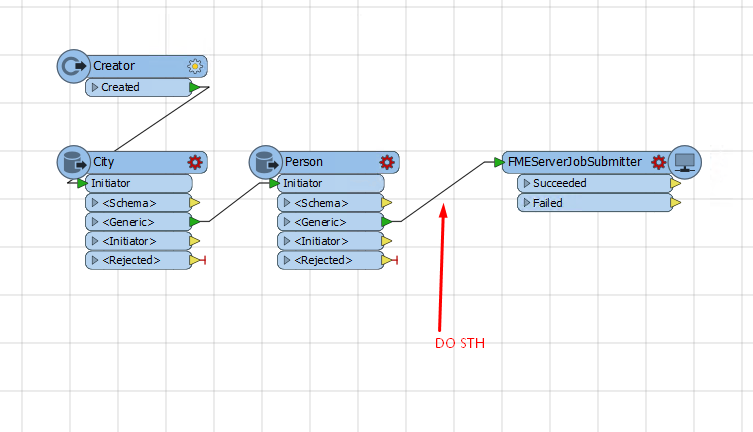
What is the best way to do that?




