



Hi everyone,
Two point datasets of drill hole locations are obtained from different sources and are of different age.
Both excel tabular datasets read in correctly and use the same projection but do not have a common joining field / key. In some cases a "holename" text string field in each dataset is very close to a string match, but often due to naming convention or case changes will not generate a match.
I have added a "source" attribute to each dataset upstream so I can trace the origin.
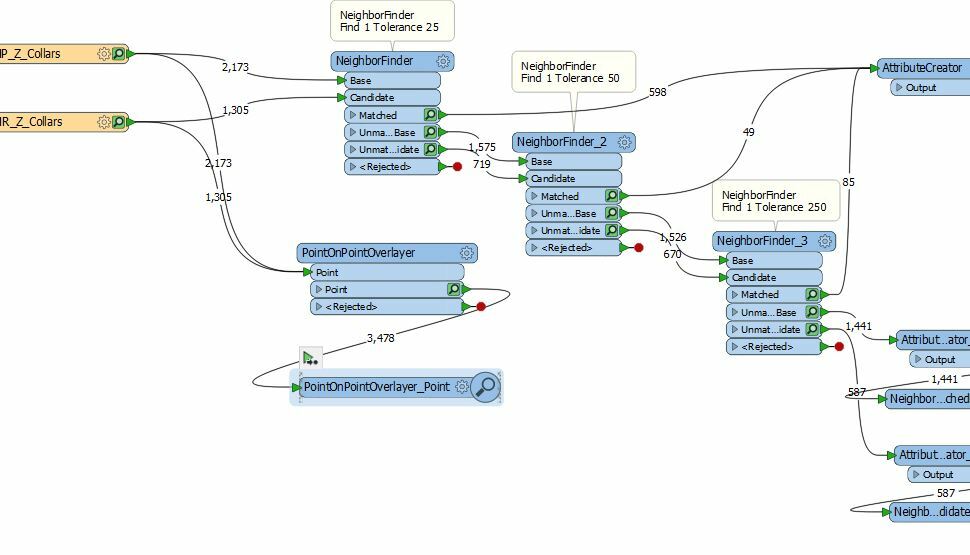
Several versions of spatial joins have been tried using either neighbour finder or point-on-point overlayer to attempt to;
1) Identify potential duplicates based on proximity
2) If duplicates are identified (and confirmed by eyeball that the holename is similar), check which of the points has the latest age , and use the geometry of the latest in a consolidated single point dataset.
Each of the neighbour finder and point on point overlay seem to have pro's and con's in this application, the most critical of which appears to be;
1) the selection of what dataset is "base" or "candidate" as the "candidates" are not removed from the search process following a match with a base.
2) the selection of the tolerance range (points may differ due to rounding error <1m or survey / original projection errors >200m)
3) The point-on-point overlayer does not return distances between points automatically, and depending on the configuration of the transformer for tolerance may or may not return potential duplicates.
I would like some guidance if anyone has faced a similar issue, or can suggest any other techniques or transformer configurations for dealing with such unfriendly point datasets.
Thanks in advance
