Hi Guys,
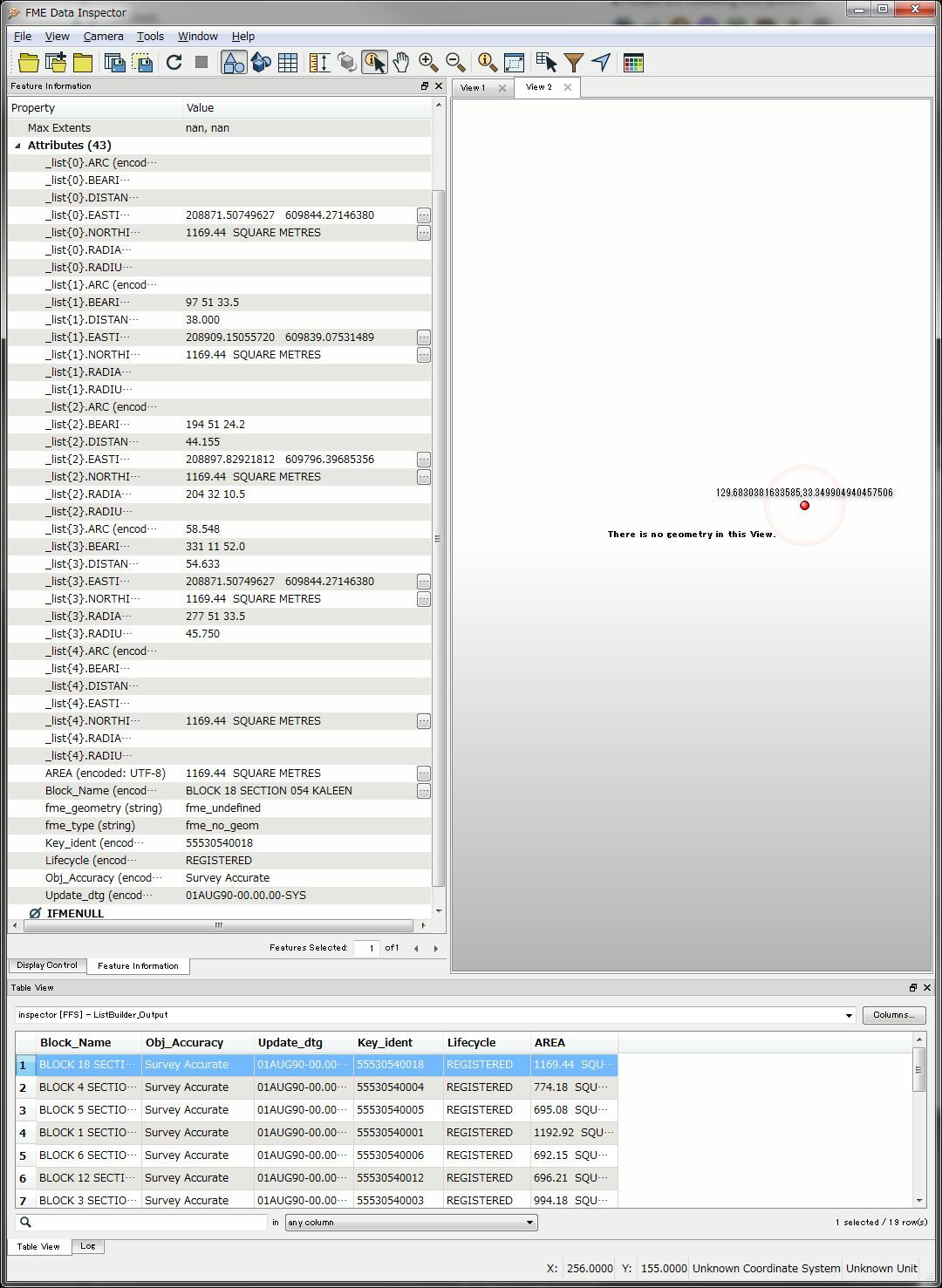
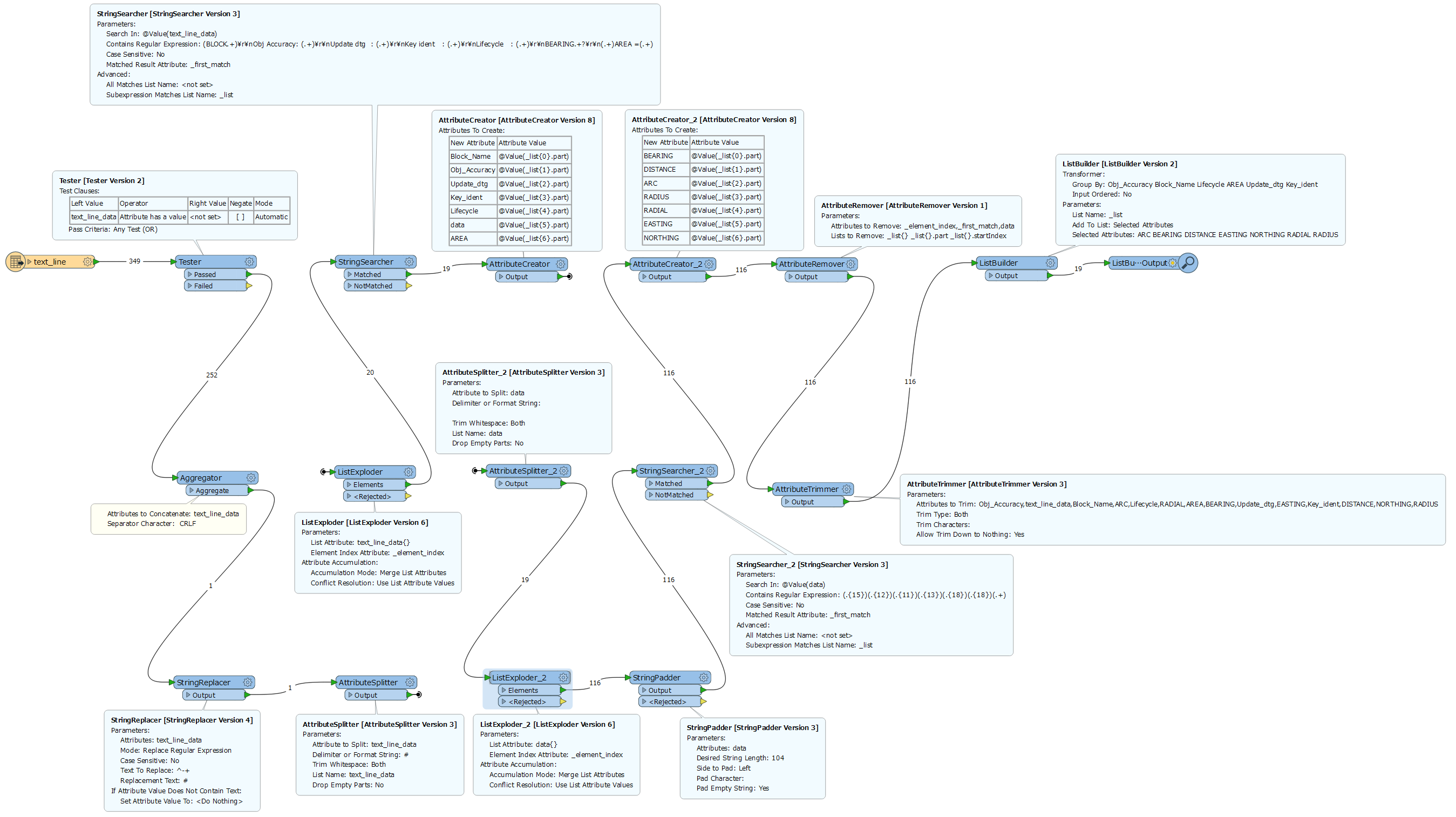
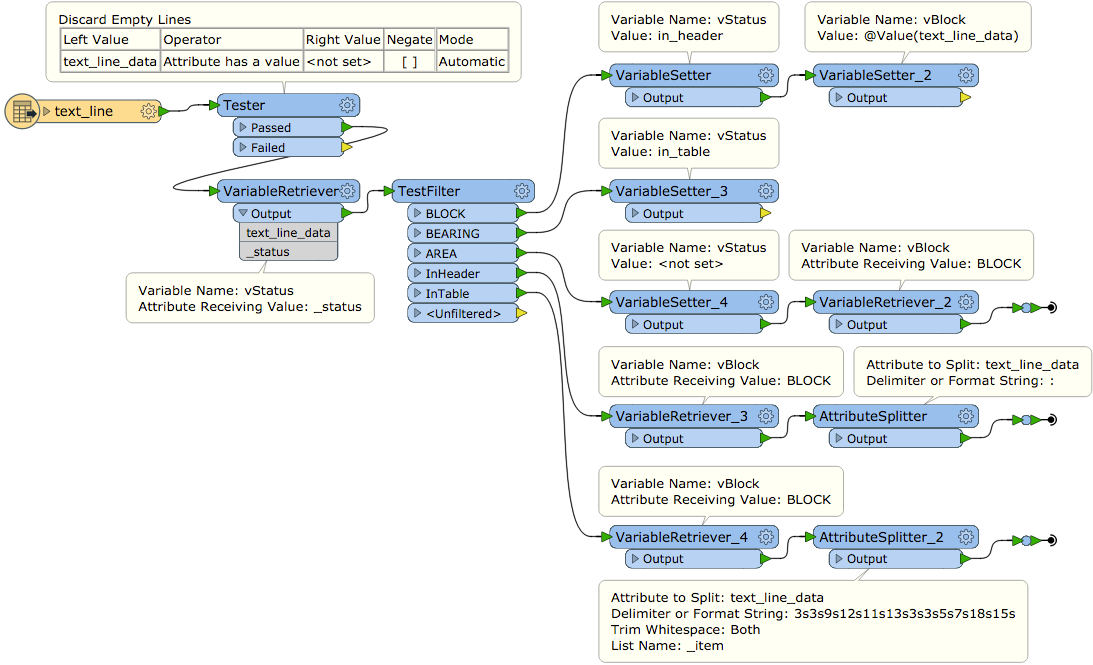
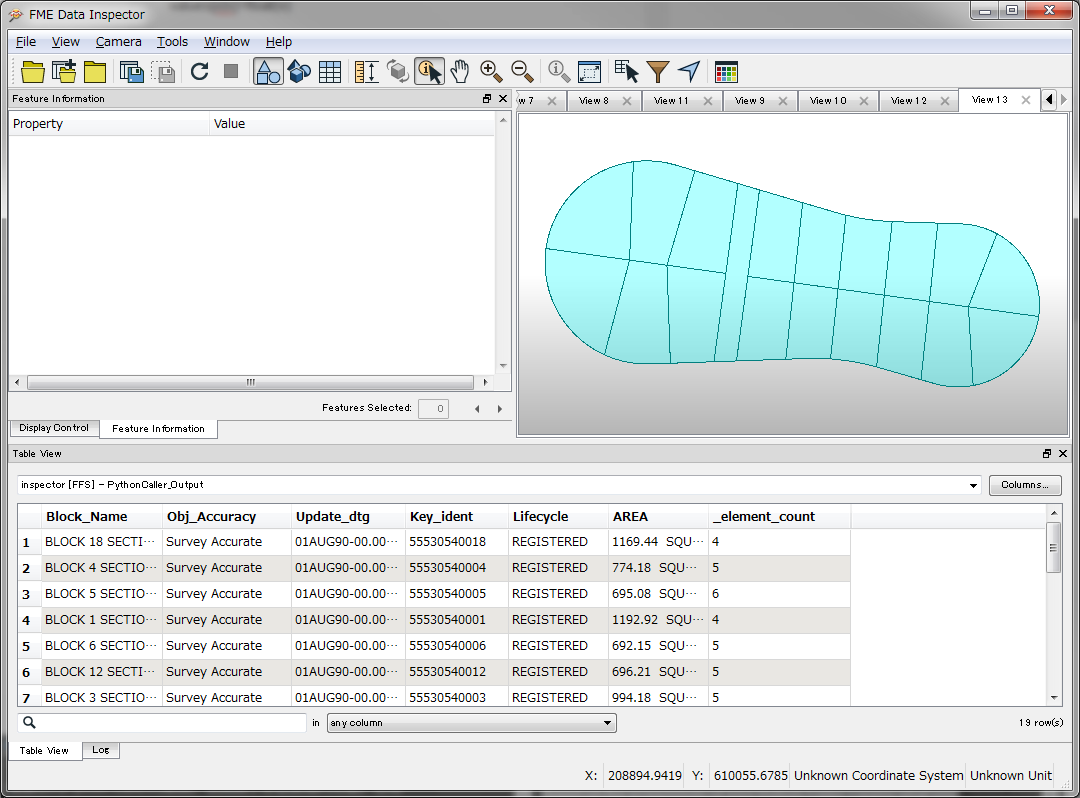
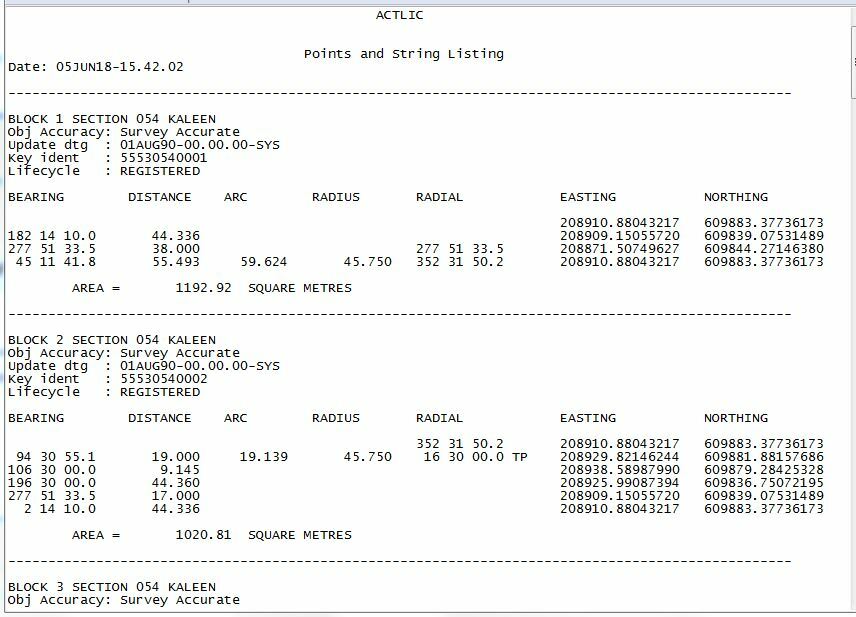
I have a text file that contains both header information with necessary attribute fields and a fixed width set of sequential coordinates with bearing and distances that create the polygons of a cadastre. I need to create the polygons with the attributes attached.
If I read in the file as a CAT, I can't find a way to retrieve the attribute information at the top
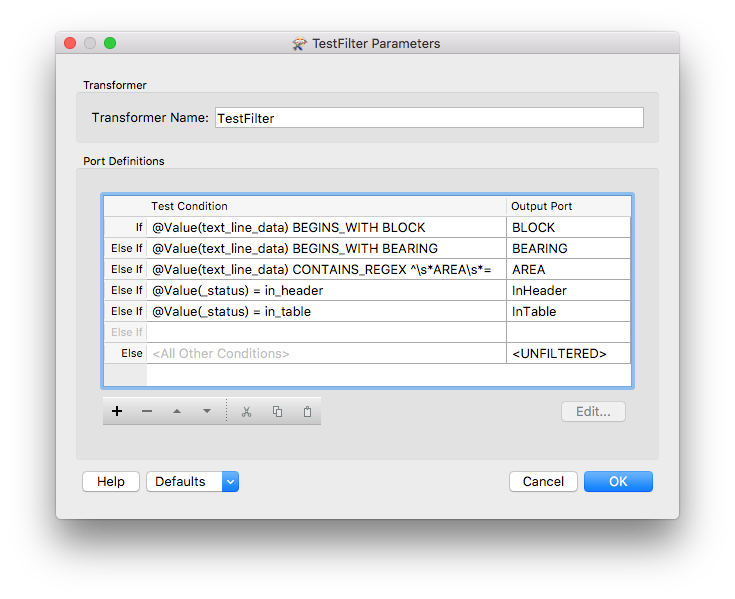
If I read it as a text file, then split on the ----, I can sort of retrieve the header information as attributes, but then can't figure out how to extract the fixed width stuff into lists.
Also, all the the blank spaces are causing me issues in creating a set of headings, especially as the first line of the definition is blanks until you get to the radial, OR the E/N.
I was going to try to read these in as a sequential list - ie, each feature is also referencing the one before and the one after... it should be relatively easy to do!
Any thoughts on the best way to do this? Sample text file attached.
(Definitions: I believe that bearing is the baring of the surveyed line, distance is chord distance, arc is arc distance, radius is radius of the arc circle part, radial is the angle at the start / end of the arc, TP stands for Tangent Point - not sure why TP is inconsistently applied though)
Thank you!!
Best answer by takashi
View original