I have to regularly import a bigger number (200+) of CSV-files into postgis, and obviously dynamic reading of those files is the way to go.
Before coming to FME I did this with the help of ogr2ogr Version 2.xx, which honors the presence of a CSVT-File that contains in one line the data types of the CSV-File, separated with commas. (see http://www.gdal.org/drv_csv.html)
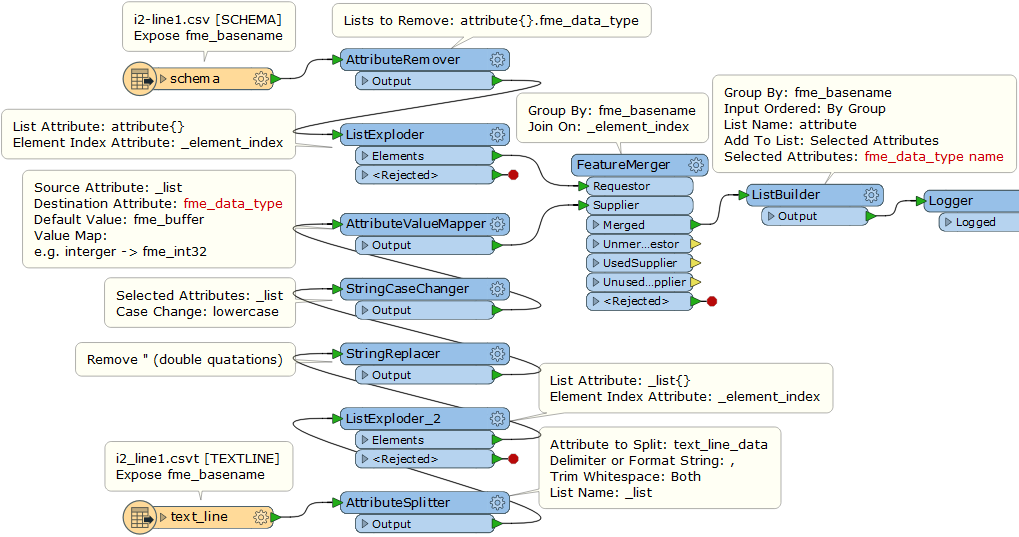
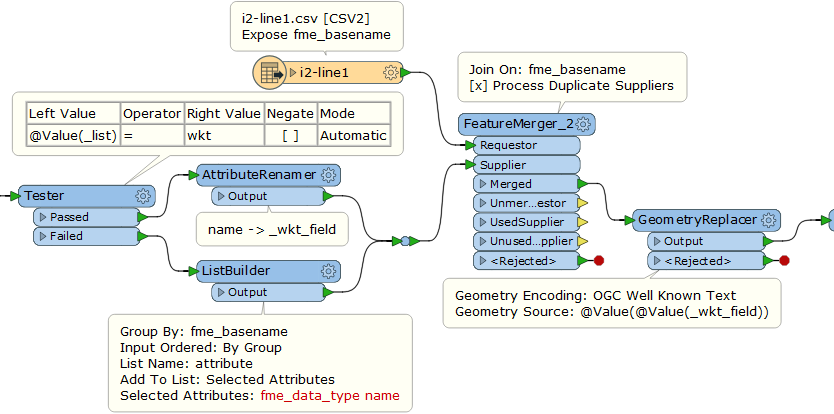
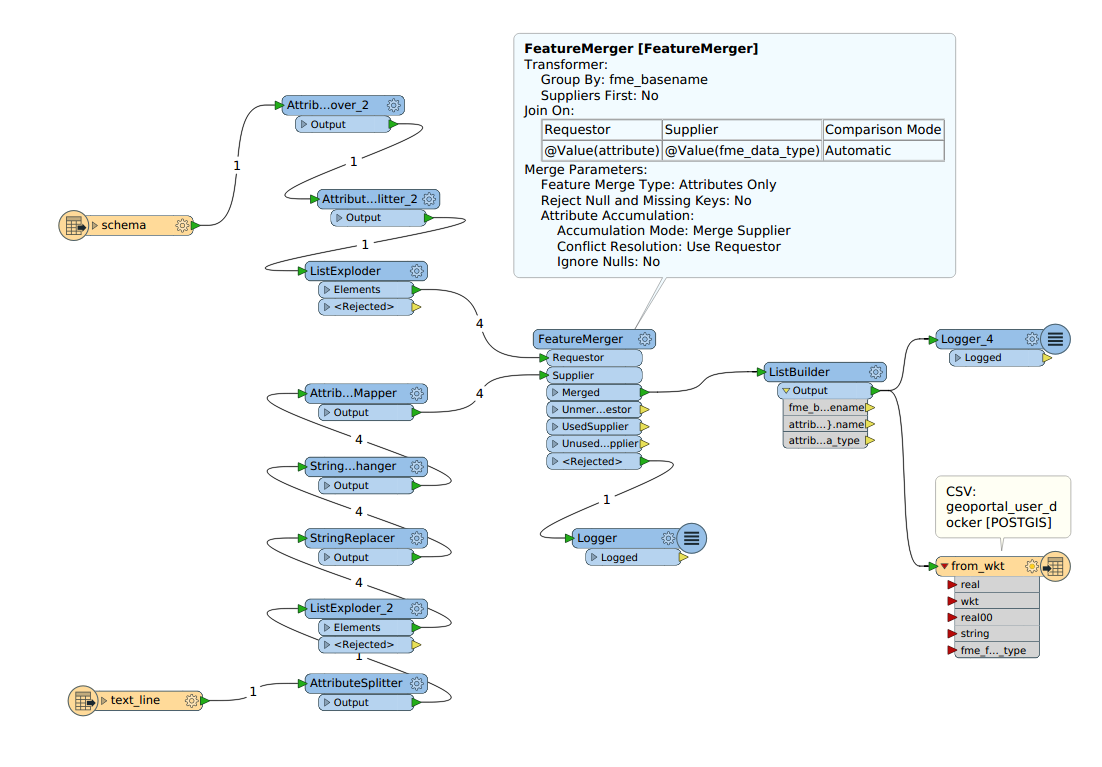
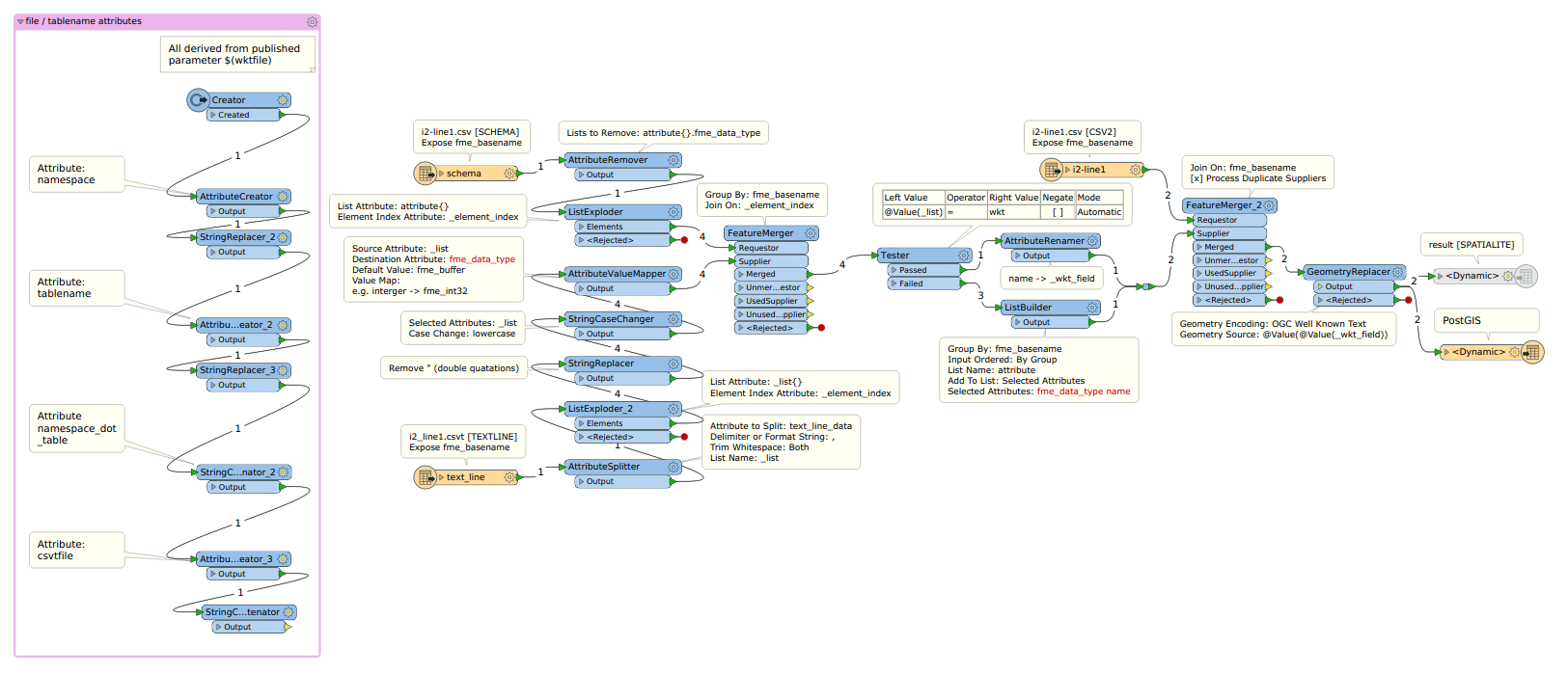
What I am now trying to do is to dynamically create the table structure with FME means by reading
* the first line of the csv-file (), which gives me the column names, and
* the one and only line in the csvt-file ( - the suffix is .csvt, but the uploader complained), which gives me the data types in the same sequence as the table names are.
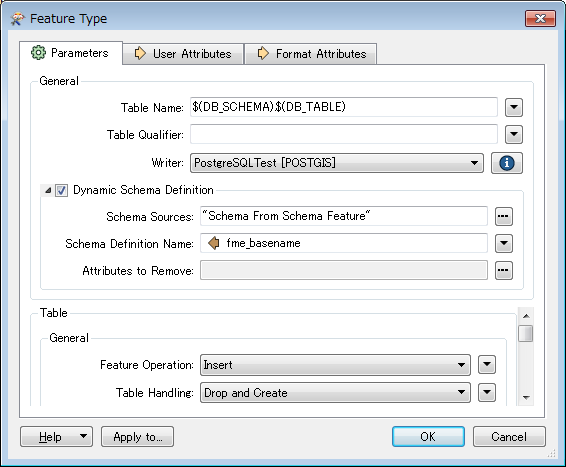
My first draft looks like this:
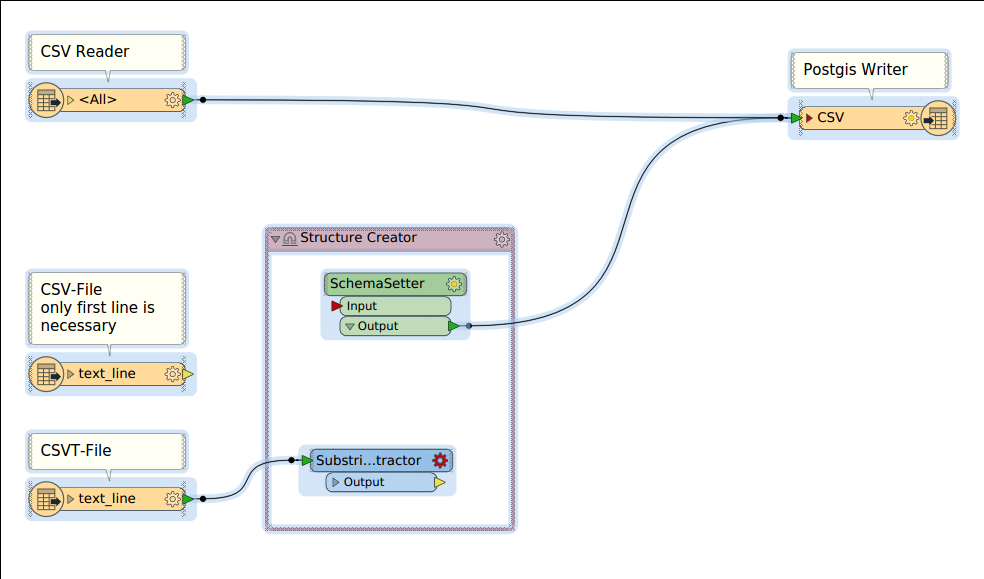
I guess that a ListCreator and a SchemaSetter should accomplish this task.
Alternatively, I could imagine to write the structure creator in python, but have no idea how the structure data has to be formatted.
Goal is to run this workspace in FME-Server and submit to it only the CSV-File to be imported, deriving the table name from its filename.
Any help would be greatly appreciated.