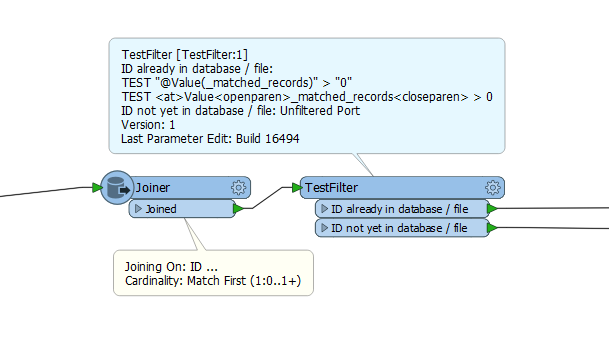
I have new data which I need to load into an existing table, but need to check if an ID number exists in the original table. If it does exist in the original table then I need to move that record to a new table and insert the new data into the original table..
I hope that makes sense, but what is the best method to check if an id exists and move it.