I would like to join features from two data sources based on a datetime attribute. However I would like to apply a tolerance as the rounding varies ever so slightly in the two datasets. So for example a feature in one dataset has a datetime of 20140922150020.782, while in the other dataset it is 20140922150020.783. These are essentially one and the same, however there is no "tolerance" setting in FeatureMerger for something like this: it is a very "black & white" transformer :) Are there any other workarounds or techniques for this sort of problem? I could truncate the above to 2 decimal places, but that is a bit risky for this application. A tolerance of +/-0.001 for example would do the trick. Thanks.



Userlevel 4
- 8177 replies
-
16 May 2019

There is currently no tolerance setting in the FeatureMerger, you'll have to simulate one using rounding or other maths tricks.


Userlevel 1
 +21
+21
- Contributor
- 3079 replies
-
16 May 2019

You can do the rounding 'on the fly' within the feature merger so that the original values are retained.

 +5
+5
Thinking outside the box a bit, you could turn the datetime into x/y coordinates and then use a NeighbourFinder or some other geometric transformer that does have a tolerance.

Userlevel 2
 +17
+17
- Contributor
- 7538 replies
-
16 May 2019

Alternatively the InlineQuerier could be used after convert datetime format to %Es (seconds since epoch, without time zone suffix).


 +6
+6
- Participant
- 33 replies
-
16 May 2019

Working with linear referencing, I run into issues like this a lot. What I have found as an easy approach is to take this from an attribute to a spatial approach. You can extract the original geometry (if any) then replace the geometry with X = time and Y = 0.
Once this is done you can use the neighbor finder, spatial relator, point-on-point overlay, just about any spatial transformer. Most of these have a "tolerance" and can build lists or relationships, once completed then you can replace with the original geometry. If you are dealing with a very large amount of records just be sure to sort them, it will help with processing time.
+6
- Participant
- 33 replies
-
16 May 2019
Working with linear referencing, I run into issues like this a lot. What I have found as an easy approach is to take this from an attribute to a spatial approach. You can extract the original geometry (if any) then replace the geometry with X = time and Y = 0.
Once this is done you can use the neighbor finder, spatial relator, point-on-point overlay, just about any spatial transformer. Most of these have a "tolerance" and can build lists or relationships, once completed then you can replace with the original geometry. If you are dealing with a very large amount of records just be sure to sort them, it will help with processing time.
And you know, there is something I love about FME. It's the only application where the limitation is your imagination.
If you are familiar with lists then there might be a simpler and faster way.
Create a new attribute called MERGE_BY and set it's value = datetime * 100. Using a list builder just use this GROUP_BY as the GROUP BY value. So if you use int(20140922150020.782 * 100) that returns 2014092215002078 so the 0.782 and 0.783 would be built into a list
You could also use this same approach in the feature merger by using a sampler on the GROUP_BY taking the first one of each group and use it as the requester. Send the rest to the suppliers and build a list on it.
Hope that gives you enough options!
 +6
+6
Thanks all for your responses and my apologies for the late reply. Rounding wouldn't really work as it doesn't act as a tolerance setting. Ex: if I have a value of 50.005, it wouldn't match with 50.004 if I want a tolerance of 0.001 since with a 2 decimal place rounding approach I would end up with 50.01 and 50.00. I think the best option is to turn the numbers into geometry and use geometric transformers that have the tolerance options. I might post this in the Ideas forum or upvote an existing post.
 +22
+22
- Contributor
- 1961 replies
-
5 June 2019
Could you adapt the fuzzyStringCompareFrom2Datasets custom transformer?
+22
- Contributor
- 1961 replies
-
5 June 2019
You may wish to vote on this idea https://knowledge.safe.com/content/idea/28819/enhance-featuremerger-comparison-modes-for-in-rang.html
+6
You may wish to vote on this idea https://knowledge.safe.com/content/idea/28819/enhance-featuremerger-comparison-modes-for-in-rang.html
Thanks a lot, just did and linked to this thread :)
+6
Could you adapt the fuzzyStringCompareFrom2Datasets custom transformer?
Thanks, possibly but not sure. Will have to look into it. Intuition tells me it will not give the intended results as string matching can match to something that is beyond the required tolerance.
+22
- Contributor
- 1961 replies
-
6 June 2019
Thanks, possibly but not sure. Will have to look into it. Intuition tells me it will not give the intended results as string matching can match to something that is beyond the required tolerance.
I was thinking more the logic of keyless featuremerging and exploding, so that you have a feature with attributes containing two values to compare. Instead of doing the fuzzy match, you take the absolute value of the difference between the datetimes. If it's less than 0.001 then that feature is a match.
Userlevel 1
+21
- Contributor
- 3079 replies
-
6 June 2019
Thanks, possibly but not sure. Will have to look into it. Intuition tells me it will not give the intended results as string matching can match to something that is beyond the required tolerance.
I agree that comparing the differences could be a possibility. I have used this sort of workflow in the past (it's a simple example, would require some changes to allow for duplicate suppliers etc.)
- Build a list of all values for the supplier features
- Merge list to all requestor features
- Python caller to evaluate the difference between valueA in the requestor and all possible valueBs from the supplier, if there is a value with a difference of less than the tolerance, create an attribute with the b value.
- Use another featuremerger to merge using the newly created attribute and the original suppliers
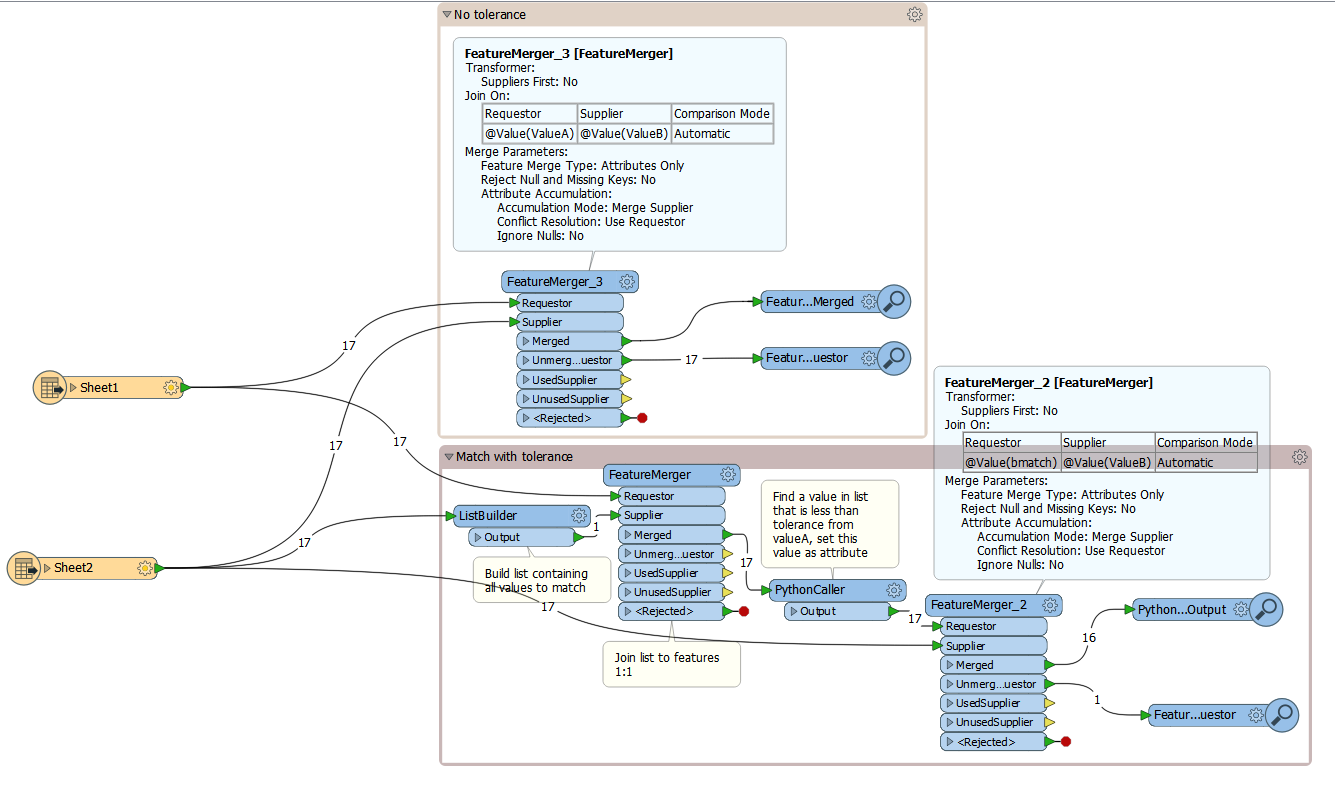
merge_with_tolerance.fmwt
+6
Wanted to pass along another transformer that has helped (somewhat) in a similar quest: NeighborhoodAggregator. Use case: read text data from PDF and create lines of text based on the position of each block (by extracting the point coordinates, using a BoundsExtractor). I was then able to build a list of needed attributes and operate them as needed (ListSorter & ListConcatenator). This use-case didn't require a FeatureMerger, but thought of adding this to the post just in case it's useful to others reading this. In this example, I had minor differences with the Y position of the text blocks, but needed to aggregate them as if they were collinear.
Reply
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.