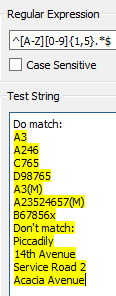
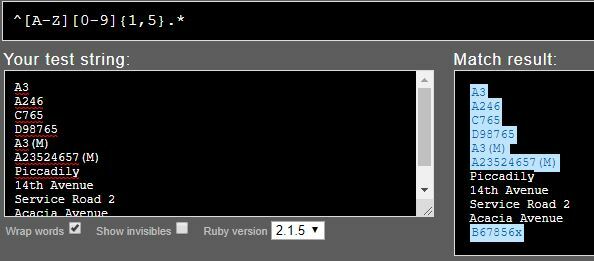
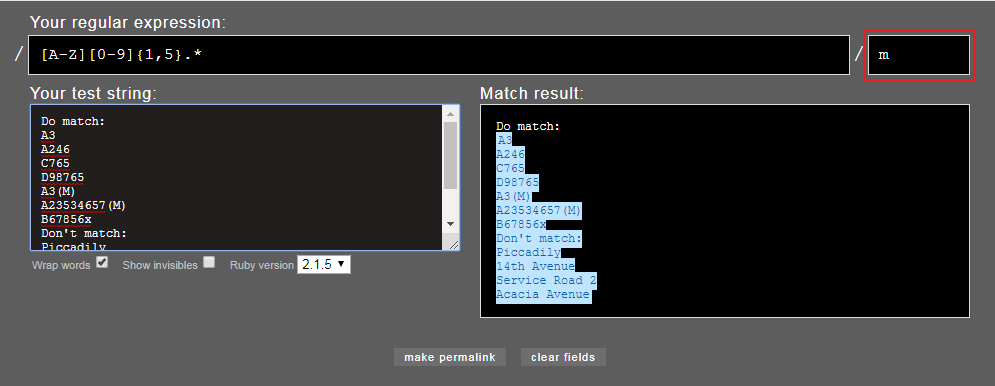
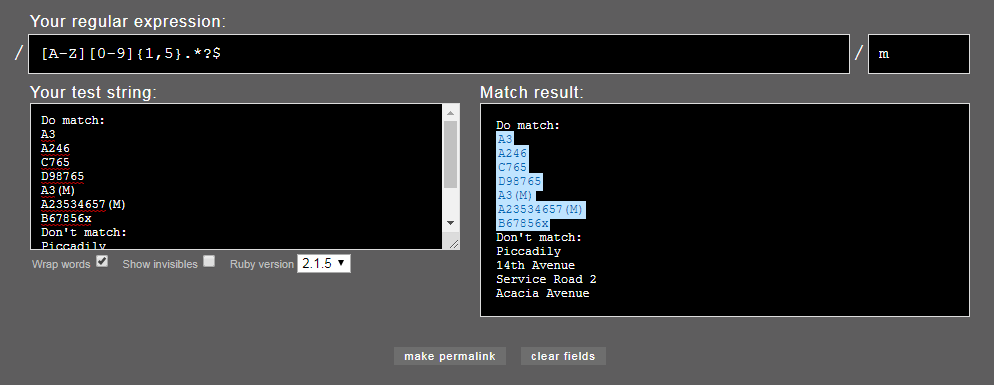
I've written a regular expression for StringSearcher to separate features with road names (e.g. "Acacia Avenue") from features with road numbers (e.g. "A246", "B3276", "A3(M)"). Road numbers start with a single letter followed by a 1-4+ digit number and sometimes suffixed with further characters such as "(M)".
However my original RegEx mistakenly treats values like "Service Road 2" and "14th Avenue" as road numbers when they should be treated as road names. I've updated the RegEx to this: ^[a-zA-Z]{1}[\\d]{1,}.{0,}$ but it's still not filtering correctly. If I put square brackets round the dot (any single character), it correctly gets "A246" but misses "A3(M)".
Best answer by ebygomm
View original