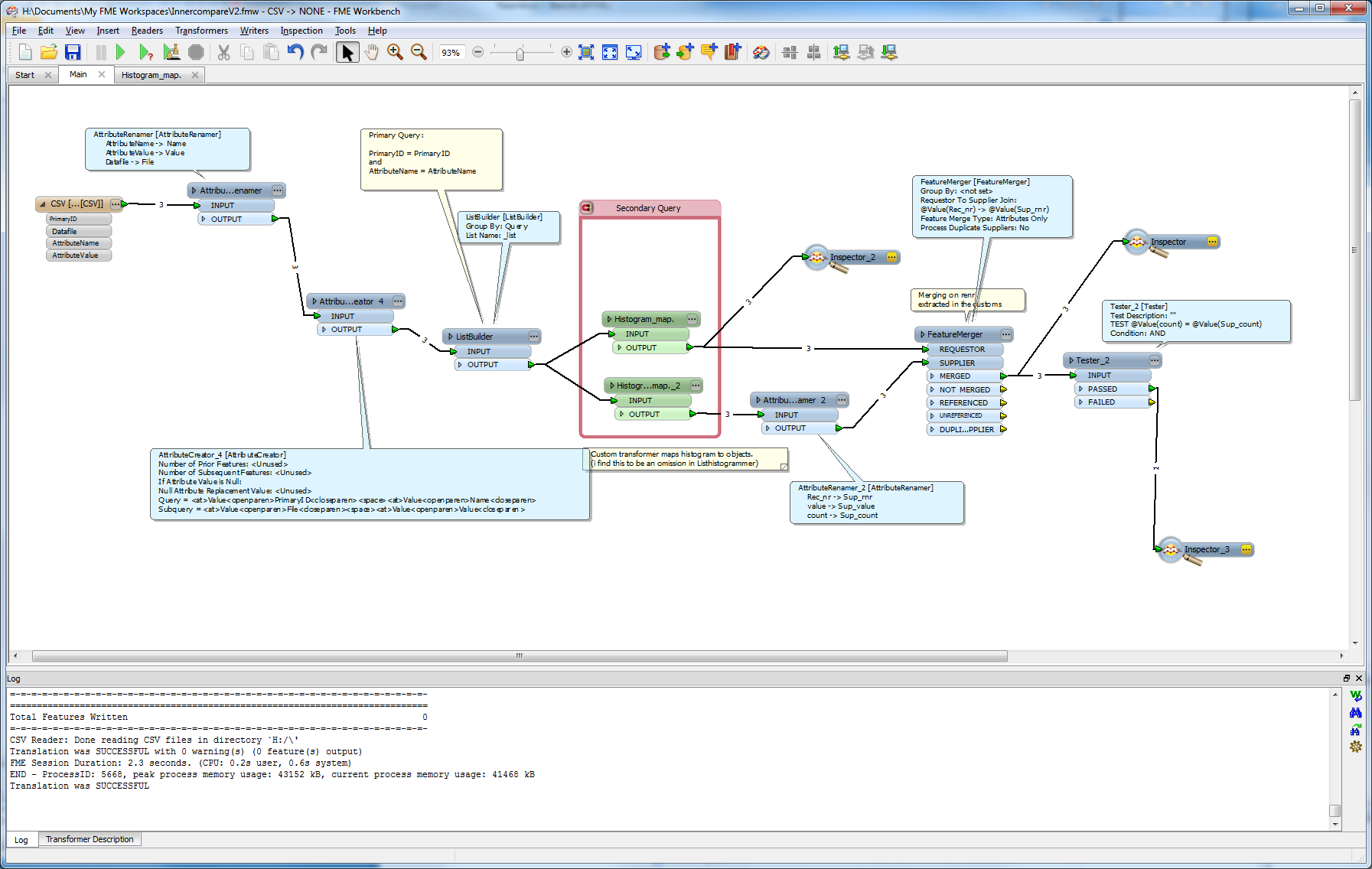
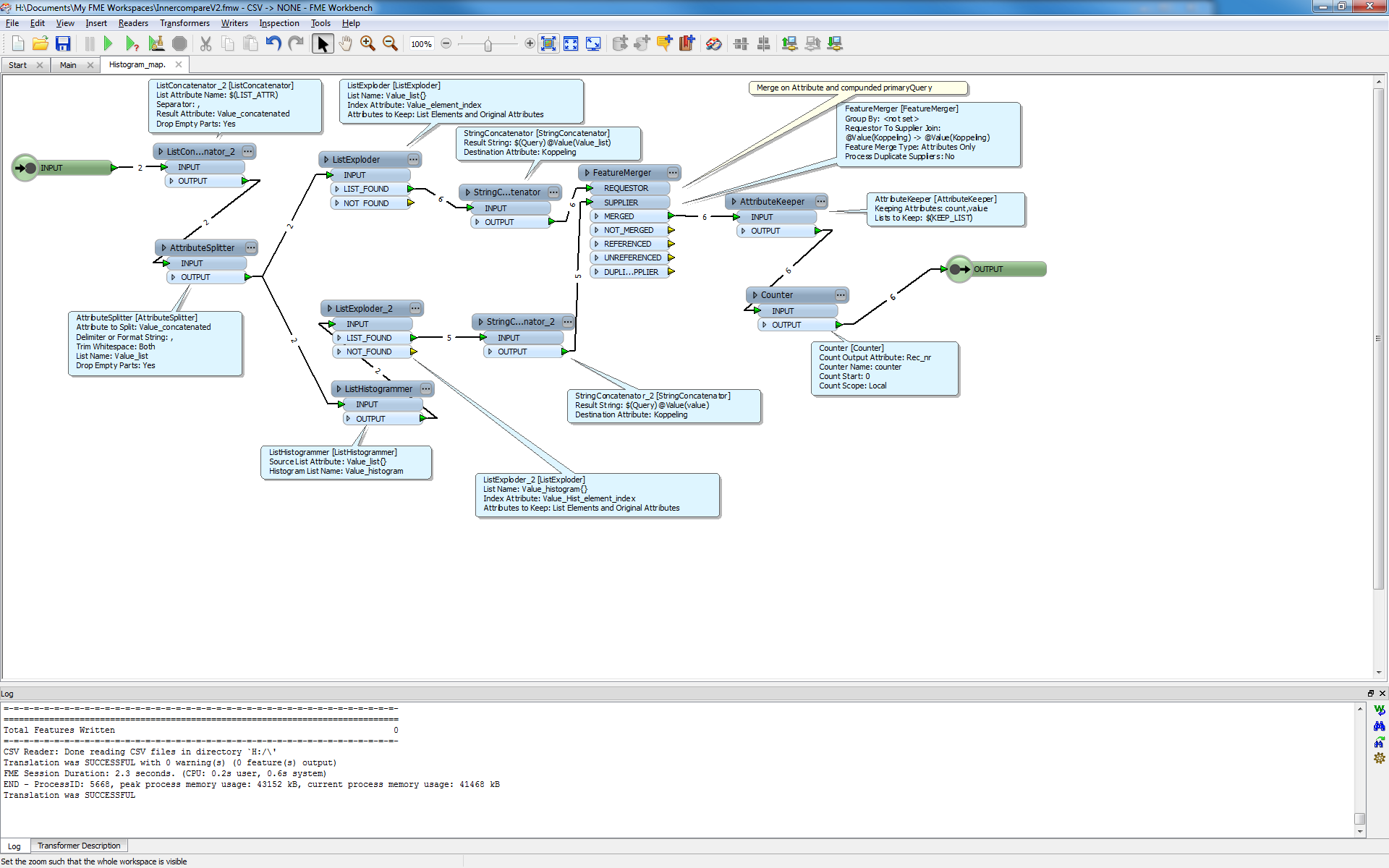
I have an interesting analytical type question that I am trying to solve in FME. I have two (or more) XML files which I need to compare for differing values in the same datatype and report on them. I have created a CSV file with a vertical datamodel of the structure
PrimaryID, Datafile, AttributeName, AttributeValue
What I need to accomplish is having FME report
Where PrimaryID = PrimaryID and DataFile <> Datafile and AttributeName = AttributeName and AttributeValue <> Attribute Value
Something like this
PrimaryID, Datafile, AttributeName, AttributeValue
1001, FileA, Engine, 4Cylinder
1001, FileA, Colour, Blue
1001, FileB, Engine, 6 Cylinder
1001, FileB, Colour, Blue
1002, FileA, Engine, 4Cylinder
1002, FileA, Colour, Blue
1002, FileB, Engine, 4Cylinder
1002, FileB, Colour, Blue
The result would be that FME would report
PrimaryID
1001, FileA, Engine, 4Cylinder
1001, FileB, Engine, 6Cyliner
As these value are different even though they relate to the same Car (id 1001) but one file reports the car having a 4 cylinder engine and the second file reports the same car having a 6Cylinder engine.
At the moment, I can have multiple XML files to read, some of which may be missing attributes, so I would need to detect those as well.
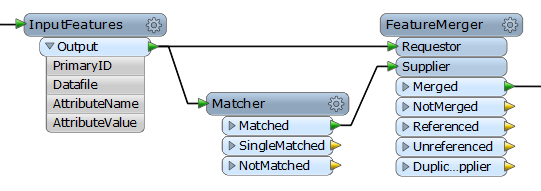
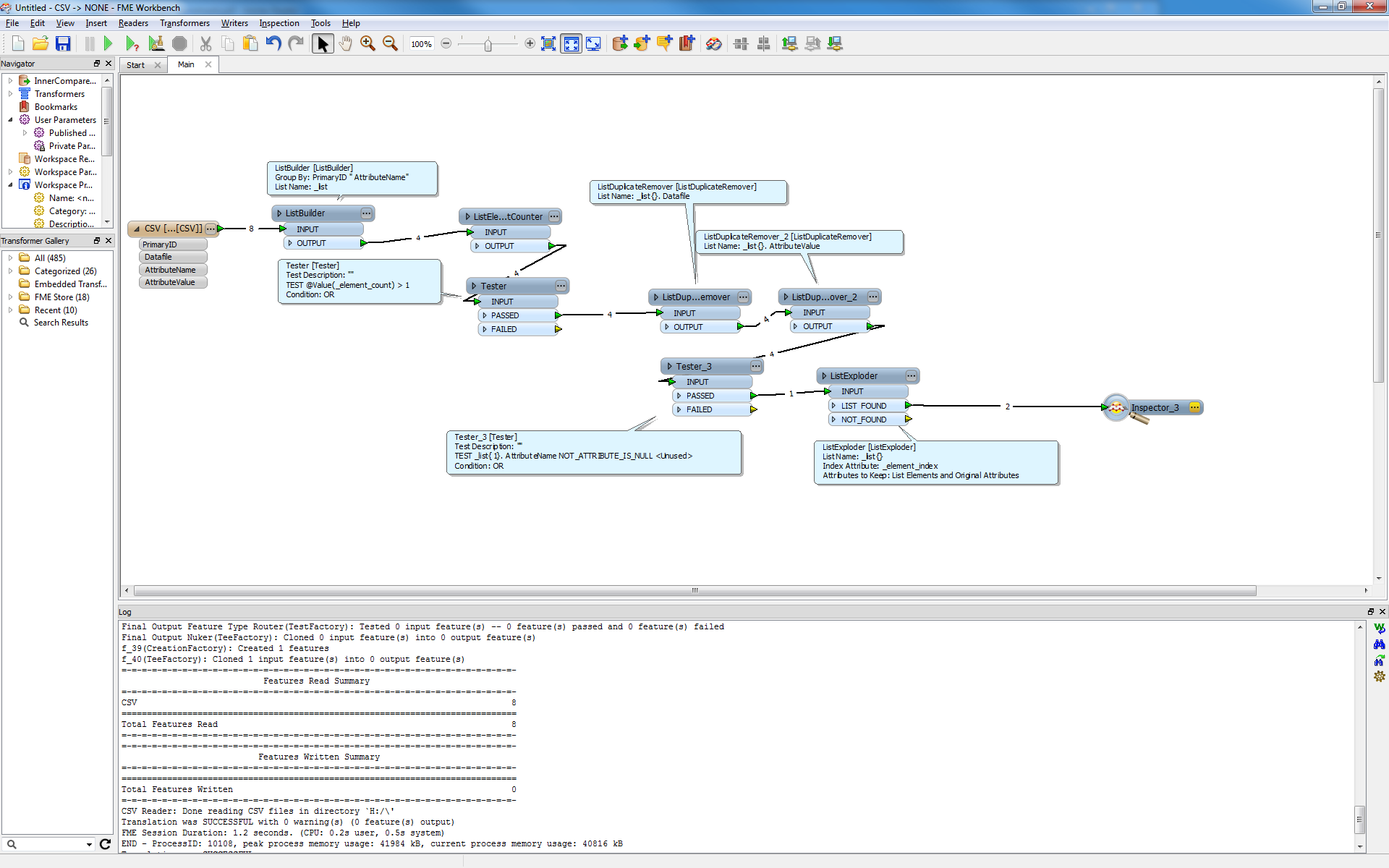
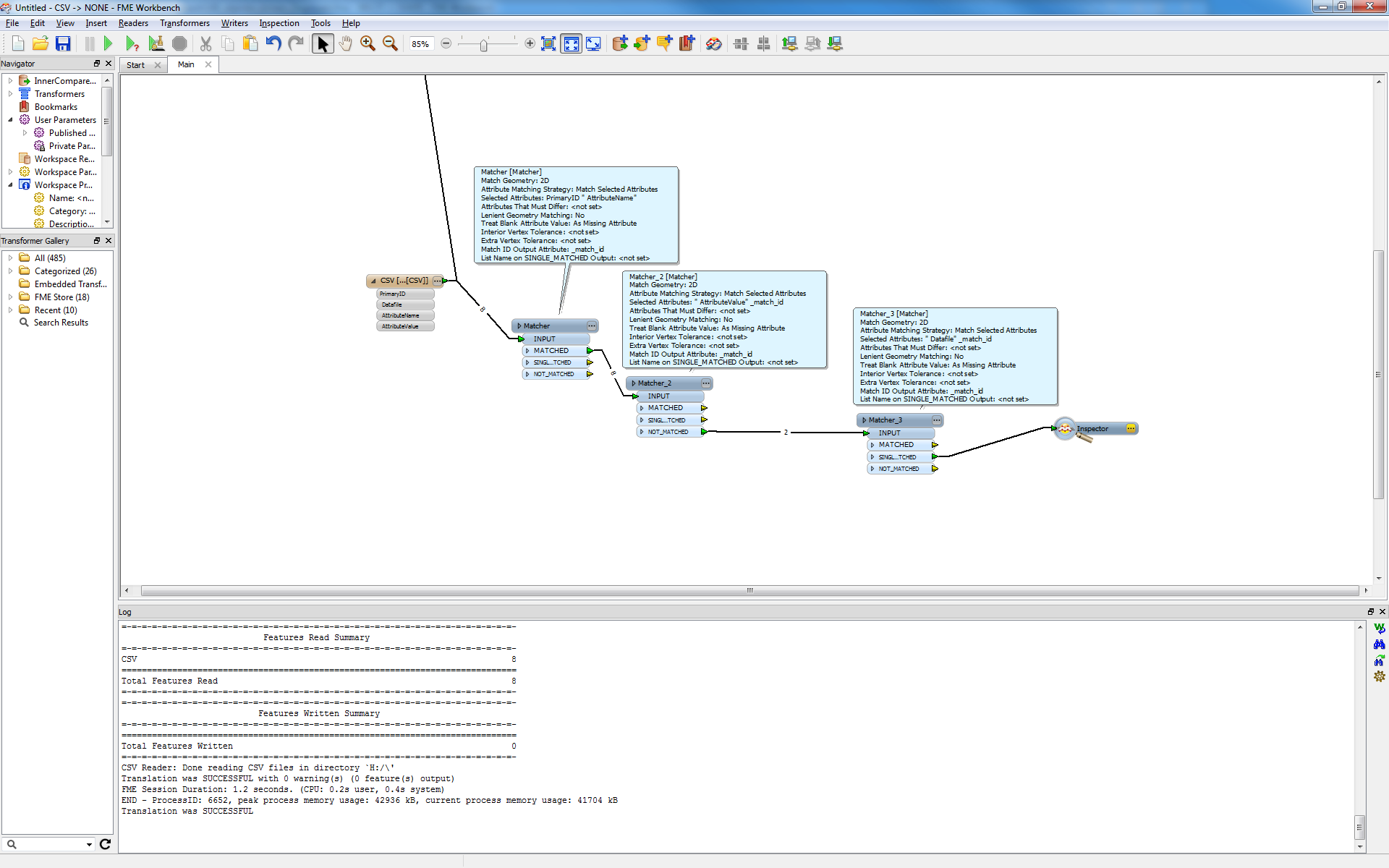
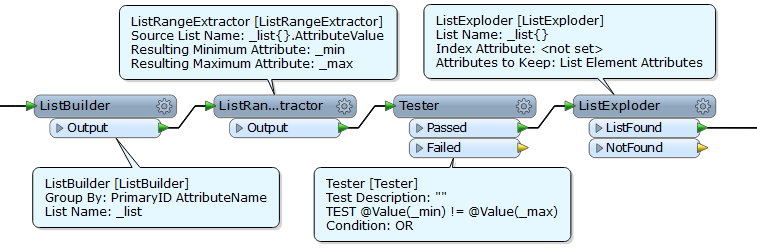
My process is to read them in, I then use an AttributeExploder to expose all of the XML tags. From there I use a matcher to match on the PrimaryID values, and so on to constrian the list to what is not matched. It is at this point that the process begins to fail.
Any thoughts would be greatly appreciated.
Thanks,
Kieren