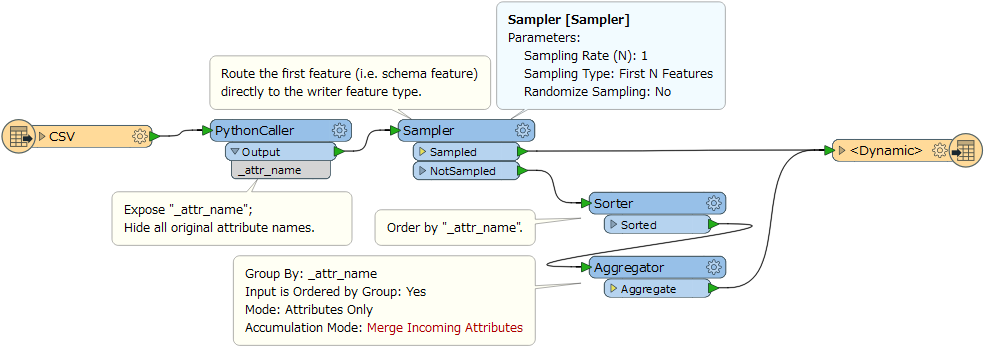
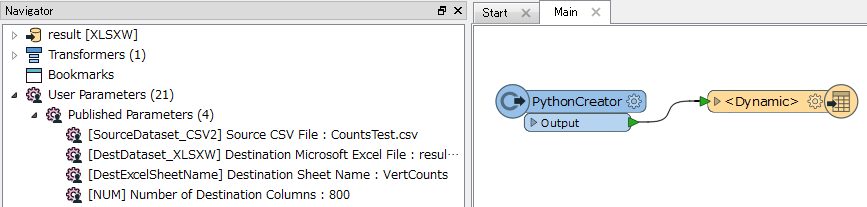
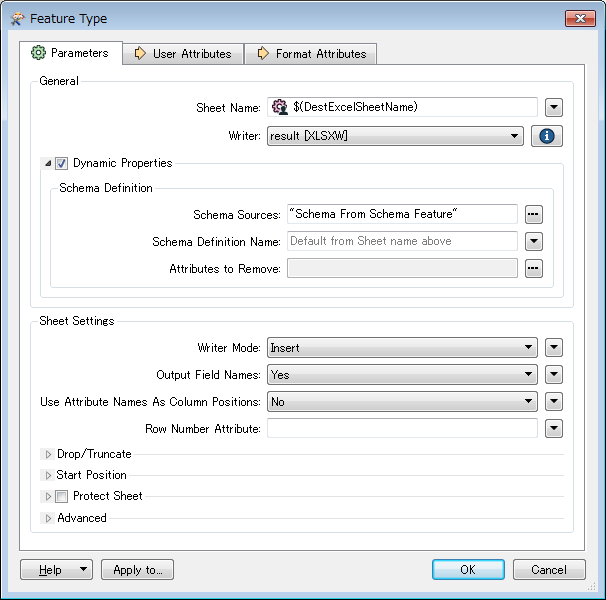
I use AttributeCreator to prepare a list of columns (A, B, C, D, etc..) for an Excel writer. My problem is that the list is 4000 items long. I have to manually expose every one of the column labels, which is not feasible. I have looked up and down and did not find a solution. Is there a way with PythonCaller to label a feature as exposed?
Best answer by takashi
View original