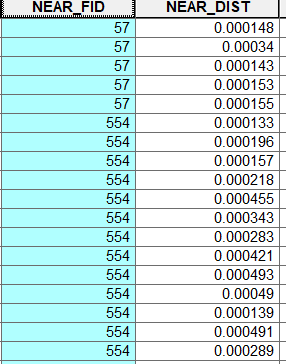
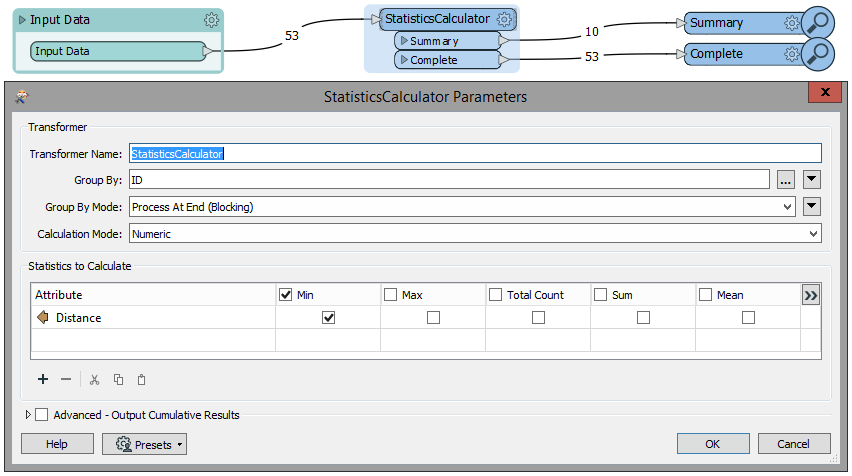
Hello Experts,
I have a file in which I have 2 columns id and distance. The distance corresponds to the ids. The issue is that some ids are duplicates and the distance is different. I want to identify the ID which has closet distance associated. See the image attached. Any help would be appreciated.